There is nothing more satisfying in “LXP land” than searching for a piece of content and finding the perfect article (or blog post or podcast or … ) on the first attempt.
“Nailing the search” not only feels good but it also ultimately:
- Saves your organisation money
- Creates a better (less stressful) user/employee experience
- Keeps people using your LXP!
Unfortunately, the perfect search result is too often just a dream — one that rarely, if ever, happens in LXPs across the world.
In most cases, employees are left frustrated as they sift through 20,000 … 100,000 … even a quarter million individual learning assets in search of the one that will help them improve on the skill they are seeking.
Luckily, the ever-elusive right asset for the right skill at the right time is not unattainable.
With that many titles in your LXP, you will need search and recommendations to be humming at a high level to make it work. In this article, we’ll discuss search (and discovery) and share how recommendations are icing on the LXP cake.
The (very brief) History of Search
Remember life before Google or Bing or Yahoo! or whatever your search engine of choice is?
Neither do I.
A day doesn’t go by when I use a search engine.
Want to know the weather today? Ask Siri.
Can’t recall who won the 1985 World Series? Ask Google.
Need to know what temperature chicken is fully cooked? Google it.
My 12-year-old asks Siri and Google questions all day long.
Not surprisingly, before Google, search was, well … less than ideal. Google makes search look easy but search is hard (as Seth Godin wrote in 2005). A few years after Godin penned that short post, Udi Manber, Google’s VP of Engineering, shared a presentation titled, Search is a Hard Problem.
The historical default is that knowledge was hard to find, particularly when it comes to learning valuable skills.
Fortunately, in many ways, search has improved 100-fold since the early 2000s. But it’s also been made more challenging by:
- WAY more content
- WAY more channels to search
- WAY more diversity of types/formats of content
But here is the rub: By being really rather good at search, especially for rich learning content that can rank millions of articles for common searches, Google makes our LXPs look bad.
Most LXPs have trouble matching (or even coming close to) the awesome power of Google’s search.
Again, did we mention search is complex?
And that’s not even considering enterprise search — a different, and in many ways way more difficult of a “search engine” compared to Google. Enterprise search can be really really hard.
Stop blaming the software
We complain about the software.
But it turns out it’s not the software's fault. Not really.
As mentioned, it’s no easy task to be a (really good) search engine. Even tools like Notion and Slack don't have anywhere close to Google search.
Oh, and never mind the fact that Google has advanced knowledge graph technology, reading and tagging the whole internet according to a set of connected entities.
The flip side of that coin is this: If Google has billions (and billions and billions) of articles and pages to sift through in milliseconds, searching inside an LXP cannot be that hard, relatively speaking, right?
It is. It can be. But it doesn’t have to be.
When LXP search is bad a lot of people get annoyed
Stakeholders and leaders complain when they see a poor result after dipping in and searching for something as a test.
End users (managers included) complain because they actually can’t find what they want. For example, searching for “high performing teams” nets “Microsoft teams.” Not good. Silently, they disengage from the LXP and go elsewhere.
As it turns out, annoyed employees do not bode well for staff morale and, ultimately, the bottom line.
How to fix the discovery problem
There is no need for poor LXP search or annoyed stakeholders and leaders, and end-users.
Here is how to fix the discovery problem:
STEP #1: DEFINE YOUR GOALS
As Degreed co-founder David Blake said: “You will learn more over a lifetime of learning administered by the hands of HR and L&D than you will in your lifetime administered to you by a university or professors… It should be our skills, irrespective of how or where we develop them, that should be what determines our opportunities …”
LXPs are skill systems … NOT knowledge systems.
What do we mean?
Knowledge systems include Slack, Microsoft, Notion, Guru, etc. Even Fuse, which can be seen as a skills system, is really more of a knowledge system.
When setting up your LXP, don't boil the ocean or claim territory that isn't yours.
STEP #2: IMPLEMENT A GOOD TAGGING SYSTEM
In Filtered-speak, when we talk about tagging, we are really referring to “metadata enhancement.”
To get in the weeds for a minute: The link between a free text search and an accurate result is another system of knowledge overlaid on top of the raw text. If we know particular searches are about teamwork, not Microsoft teams, we add metadata to pick that relationship up (even in the most basic text-based search).
If that resonated with you, great. If your head is spinning a bit (like mine!), let’s just call “metadata enhancement” tagging.
A sound tagging system should be (a) bottom-up and (b) uncover what is intended.
Bottom-up: What are people actually looking for? Export that list of search terms. Then try the most popular search terms and see which ones throw up a dud. Congratulations: You’ve just found an opportunity to surface better content.
Uncover what is intended: What do you want your users to find? Buried treasure? Great content? Relevant content? Yes and Yes and Yes.
However, the basis for the “ideal” search results is skills!
Your future-looking skill framework should be blended with the search terms to tag for the content you want people to discover to help communicate about skills.

STEP #3: USE A TECHNOLOGY LIKE CONTENT INTELLIGENCE
Finally, you’ll need to review all of the content in the LXP and tag it (or sometimes just add extra text into descriptions) and then reimport the content.
In other words, you probably need Content Intelligence.
Results Matter
We can tell you that Content Intelligence is the answer to finding (everything) in your LXP. But we are biased.
Instead, we believe in results speaking for themselves.
Filtered uncovered significant issues with discovery via search for a major global bank. These challenges were mostly driven by the simplicity of the search algorithm and problematic and insufficient metadata in the content.
We found 90% of the results were irrelevant for some popular search terms. Yikes. That’s a lot.
Good news: With a combination of tidying things up — languages, erroneous tags, etc. — and our skills tagging, we reduced irrelevant results to just 10% for these important searches. 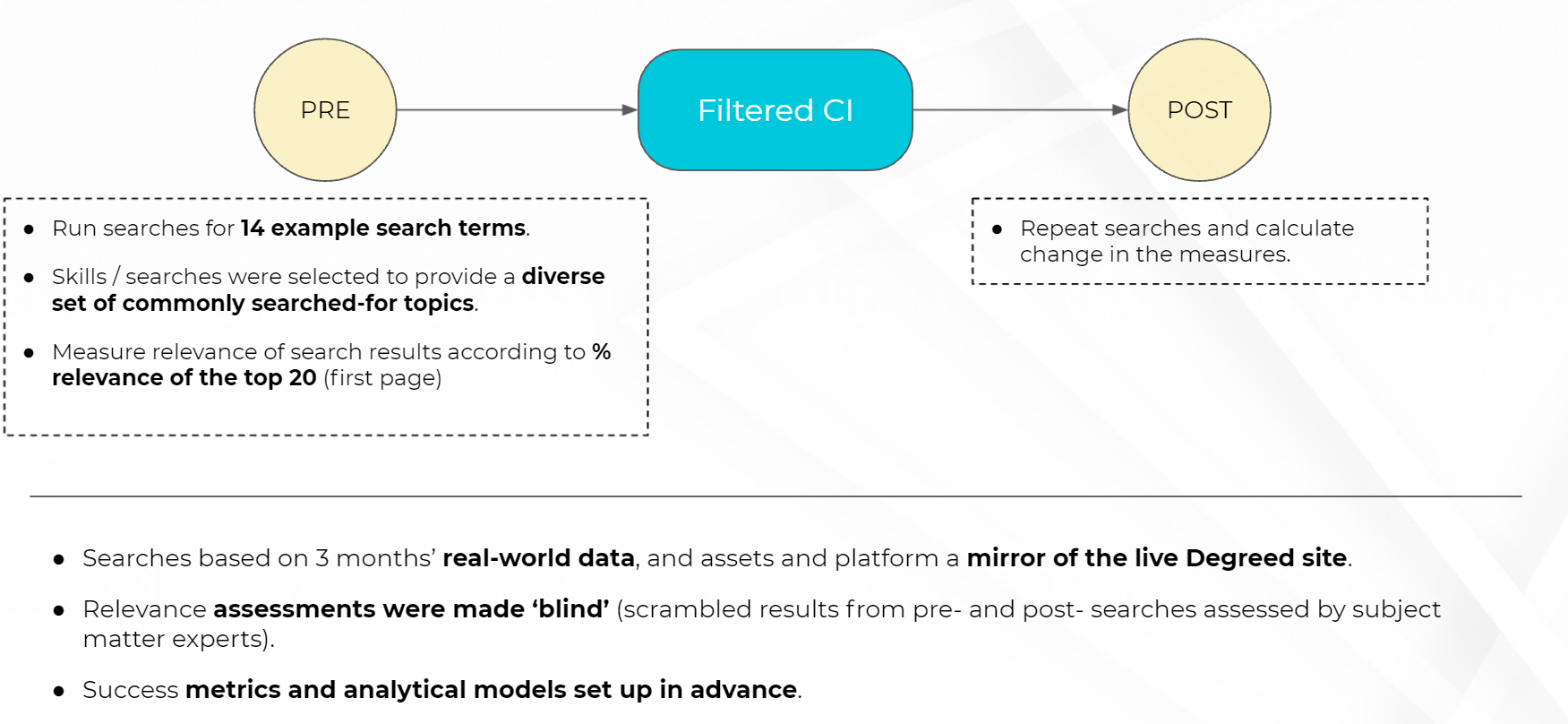
Learn more about how Degreed is using Content Intelligence to give you more relevant search results:
