What kind of experience do users have when exploring your learning platform?
What we might term “content health” is a big factor. If users encounter learning resources with no description, broken links or unsuitable content that makes for a bad experience. This article is about how you can use data (with the help of Filtered) to assess content health at scale and cleanse your library.
Let’s say we have a library of over 100,000 learning resources to look at. What criteria should we use to assess content health? Well, the starting point is taking a look at an individual resource. How would you assess its health?
Everyone has slightly different criteria, but probably you'd look at:
- Is there complete metadata? Title, description, duration, format, language availability?
- Is it relevant to the skills that matter to your company?
- Is it obsolete - is the information out of date?
- How about quality or suitability - is it offensive? Are there dead links?
Unhealthy content on these measures would merit two possible actions: update it, or delete it.
Now, you could comb through every piece of content like this and the result would be a pruned, up to date and high-quality library. But would it? Your system gets updated with new content fast. By the time you were finished, there'd be a whole lot more content to check.
Instead we can use data to run a health check on a whole content library at the same time.
Filtered has plenty of features that help us run a content health check.
The below took me about 1 hour to do.
Metadata completeness
First, I filtered by empty fields on the metadata I'm keen on: description, duration, date published, imagery. I found plenty of items with missing data:
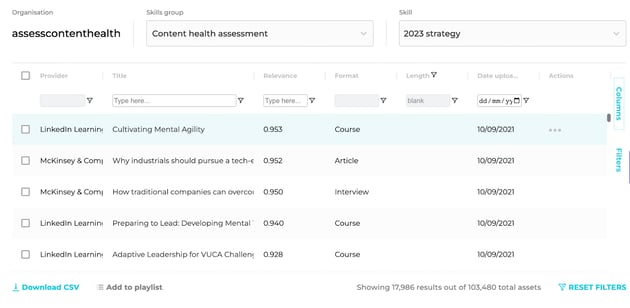
Now I need to choose whether to update or archive the problematic content. That requires me to understand the relevance of that content:
Relevance
I can run this check by filtering the messy content against my priority skills (here summarised as ‘2023 strategy) using the available data. Only relevant content should be considered for a fix:
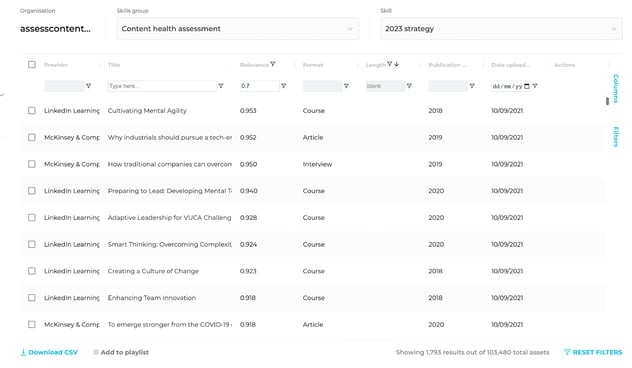
In the end I was able to archive most of it: there were only 1,793 left in the pool to consider for updated metadata. But I want to go further: I only really want to work on content which is both relevant and up to date. So let’s look at what might be obsolete.
Obsolete content
I refined my skill definition to include only content which is perishable - the kind of tech-based material that really doesn’t age well. I then filtered all the content reaching the relevance threshold against the date of publication. I decided that anything older than 2019 had to go.
Now I’m down to just 1,089 articles that are worth updating:
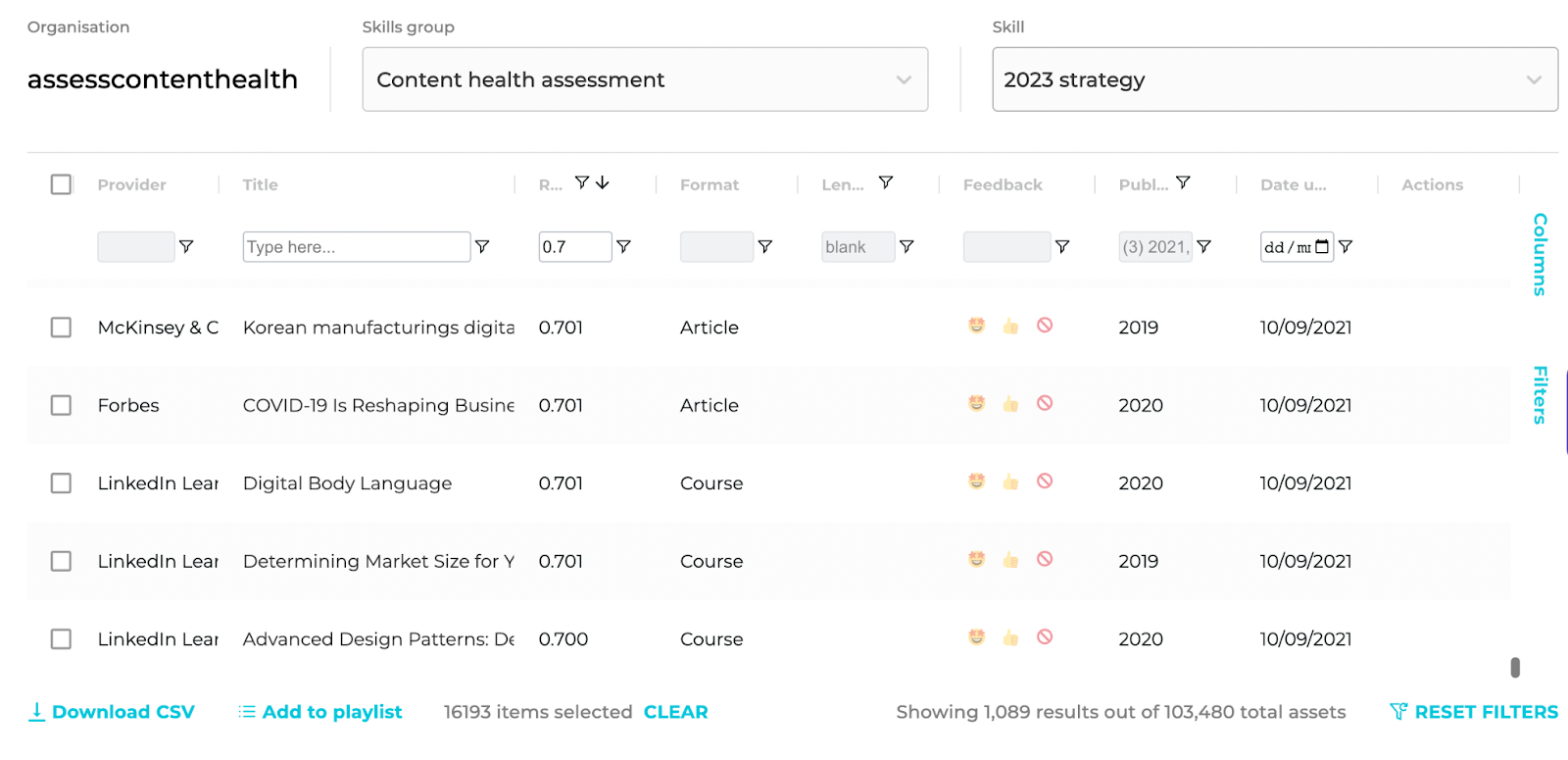
Note: you’d probably want to run this check on all of your content, regardless of metadata completeness!
Quality
Quality is the final check to make on your remaining content set. There's lots of ways to assess quality and suitability and every organisation is different. In this example, I looked at three areas:
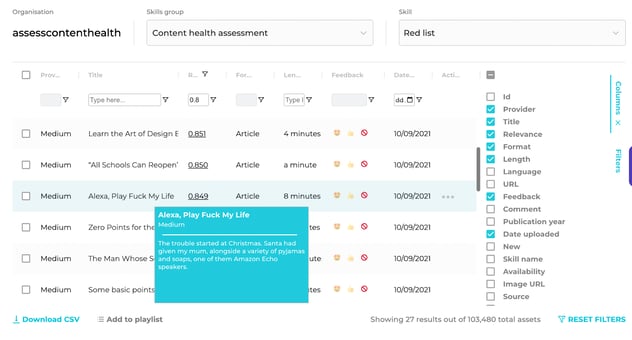
1. Unsuitability
In Filtered I used the Keyword Algorithm (which runs off of a simple check to identify certain keywords and weight them) to define a red list of problematic language (swear-words, or language that doesn’t work for my audience). Anything flagged (using the options in the feedback column) here goes in the bin!
2. Providers
Providers can also be a good proxy for overall quality. On balance, I decided that keeping Medium in was not a good idea. It’s a great source, but I really can’t verify the content’s truth or suitability easily.
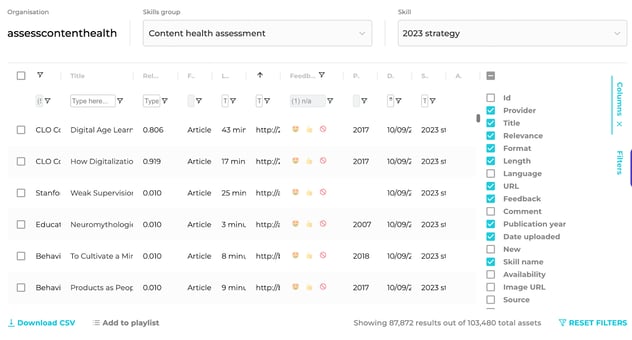
3. Dead links
Finally I checked the content for dead, absent or unusable links (you can easily add a script to do that in Google Sheets):
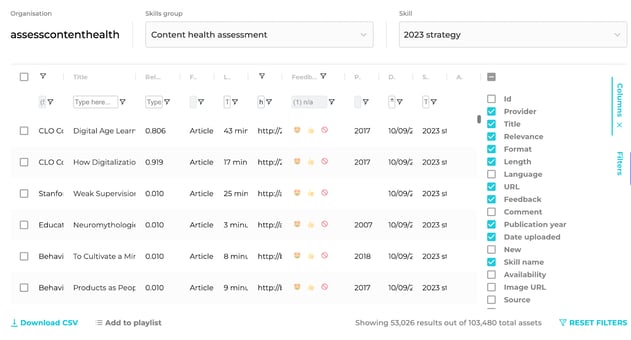
The result? My original 103,480 items have been checked and cleansed of:
- Incomplete metadata
- Out of date content
- Unsuitable content
- Dead or unusable links
The result was a library of 53,026 items, with a pool of 1,089 items to consider for an update. It feels good.
But there’s a stark reality too: before my cleanse, almost half of my whole content set was problematic in one way or another. If a user were to click at random before the cleanse, they’d encounter something that didn’t make the grade half the time.
It doesn’t take long to use data to run a health check on your content. Everyone should do it. However, the faster you work, the more likely you are to sweep away content that deserves to be archived. If you have a Content Intelligence tool like Filtered, you can make sure you pick out the relevant content (about 1% of my example set) that deserves an update.