Artificial intelligence. The next great step forward for humanity? A convenient chauffeur for self-driving cars? Or the killer drone-wrought demise of us all? Regardless of which side of the debate you’re on (and there have been some good ones recently), AI undeniably holds the potential for the next global revolution - one on par with the cognitive, agricultural and scientific.
Thankfully, the only thing that AI in learning and development will be killing off anytime soon is prescriptive, irrelevant, lowest-common-denominator content. Forget self-driving cars, we’ve now got self-driving learning, with all the effectiveness and time-freeing benefits that come along with it.
We're one of the few learning and development teams who’ve been working seriously with AI for a significant period of time. For example Matilde, who’s been with Filtered since completing her PhD in particle physics in 2013, patented our first recommendation algorithm in 2014. We’ve learnt a lot about what to do - and more importantly what not to do - when you’re building an AI-powered Smart LXP like Filtered.
As the industry as a whole begins to wake up to the potential of AI in learning, we thought it would be a good time to share some of these things to avoid. All of them are important to bear in mind if you’re thinking about implementing or developing an artificial intelligence learning solution.
- Cold Starts
- Expecting the AI to do all the work
- Rigid frameworks
- Meaningless metrics
- Setting and forgetting
- Missing the bigger picture
- Trapping users in bubbles
- Failing to optimise processing time
- Not valuing the privacy and consent of employees
- Not upskilling your team
1) Cold starts
AI is fundamentally dependent on data. It’s the oil that powers the cogs of the machine (learning). That leads to the infamous cold-start problem. Basically, if a system doesn’t have enough data on its users, it can’t draw any inferences (and make good recommendations) until it does.
That’s a problem, and quite a big one. Imagine rolling your new learning project and then having to tell your stakeholders “uh… it’s not actually going to work that well for 6 months while it collects data and users have a bad experience.”
So how to start hot and make sure your recommendations make sense straight out of the box? You need relevant data. Think about it like starting a car with a full tank of fuel. We do this using swathes of anonymised data from professionals like you. We structure in such a way that the AI can leverage a pre-existing understanding of the relationship between user characteristics (e.g. role type) and capability requirements from a master skills framework. This lets us make great recommendations straight out of the box.
There’s always data you can use for this in every organisation. You just have to find it.
2) Expecting the AI to do all the work
One of the great advantages of AI is the flexibility of its processing power. But you can’t just chuck in whatever data you want and hope the machine learning will sort it out. In that respect, current-generation artificial intelligence is much like a human - garbage in, garbage out.
Additionally, machine learning-led content can also have a tendency to career off into the extreme. The nature of human curiosity means that, for instance, each YouTube video you’re recommended is just that bit more sensational, more clickbaity until that cute cat video has morphed into a hot flat Earth conspiracy mess. That’s why even YouTube and Facebook themselves admit the necessity of human curators.
You need to do some level of manual data processing before you fire up the machine. In our case, that means a team of expert curators who are well-versed in their fields tagging quality content based on skills. Although, as you can see, we’re getting close to reaching a level of AI that can do that too.
3) Rigid frameworks
It can be tempting, once you’ve come through the initial data processing, to think “there we have it, we’ve got these two datasets that align nicely and tell us exactly what skills each user needs.” But how many members of your team are exactly alike and never change over time?
Just as they do, your algorithmic framework needs to be a continuous learner, expanding its knowledge and capabilities. And it needs to learn from a range of sources.
Almost every learning department is accruing more and more data, so try and figure out a way to incorporate that data into your AI process. magpie, for example, considers a whole host of learner characteristics such as:
- their role
- a task or goal they need help with
- their performance objectives
- their recent interests
- content they have explicitly selected to define their interest (their current bookmarks)
- the interests of similar people
This means we can serve a very large variety of use cases, from performance support to onboarding to career development to business change. And in support of a variety of client objectives, from optimising engagement to boosting relevance to supporting defined business objectives.

4) Meaningless metrics
Most of the above list is based upon user characteristics. But how do you know if your AI is performing its function in a way that satisfies those users? Too many learning programs in general, let alone those requiring the technical knowhow to incorporate AI, have fuzzy goals - or worse, none at all.
Machine learning needs to know what good looks like in order to optimise for more of it. Think carefully through the type of metrics you will be measuring before the programme starts, and be open to iterating them as it evolves. You need to be looking for signals that indicate engagement and usefulness on a deeper level. Views/opens is just a start.
For example, we optimise the usefulness of our learning recommendations by taking into account number of completions, user feedback and returning engagements to get a much clearer picture of the actual usage and impact of an asset, not just its appeal. And the algorithm itself targets more concrete attributes such as skills, rather than flimsy ones like preference, to ground what we do in value for the learner.
5) Setting and forgetting
So you’ve curated your content, set up your flexible frameworks and meaningful metrics. Things are whirring along nicely and your learners are getting some decent rex. Time to pat yourself on the back and go for a beer, right? (Given you’re on item 5 I think you know the answer to that). You need overarching dashboards that measure directly how much and at what rate your machine learning learns.
Use the meaningful metrics from the previous step to elucidate just how well your machine learning is doing. From there, you can iterate - tweak the algorithm and tweak again. A/B test, see if your usefulness score is improving. Then maybe it’s time for that beer (until the next test)!
6) Missing the bigger picture
There’s much more to be gained from AI than just optimisation. One of the great boons of processing data at scale is the ability to spot trends and to forecast. If you’re not paying attention, you might just miss that strategic insight that transforms an initiative, department - or even business!
What does that look like in practice? As we’ve established, Filtered's personalisation engine uses skills (supplemented by a host of other user behaviour measures) to serve up its intelligent recommendations. The millions of connections this creates paint a pretty picture.
By connecting all the skills in a client’s framework, we can infer a connection between skills and build what we call a skills graph - a network describing the strength of connection between each pair of skills in the framework. The graph helps our algorithms spit skills that are similar even when they’re not identical.
This not only helps our algorithms, letting them spot similar content even if its tags don’t match, but also the organisation by showing them which skills in their workforce are connected, enabling more informed creation of competency matrices and training provision - and to work out where skills gaps are occurring.
From that, you can generate actionable insights such as this one, which shows skills demand against content provision:
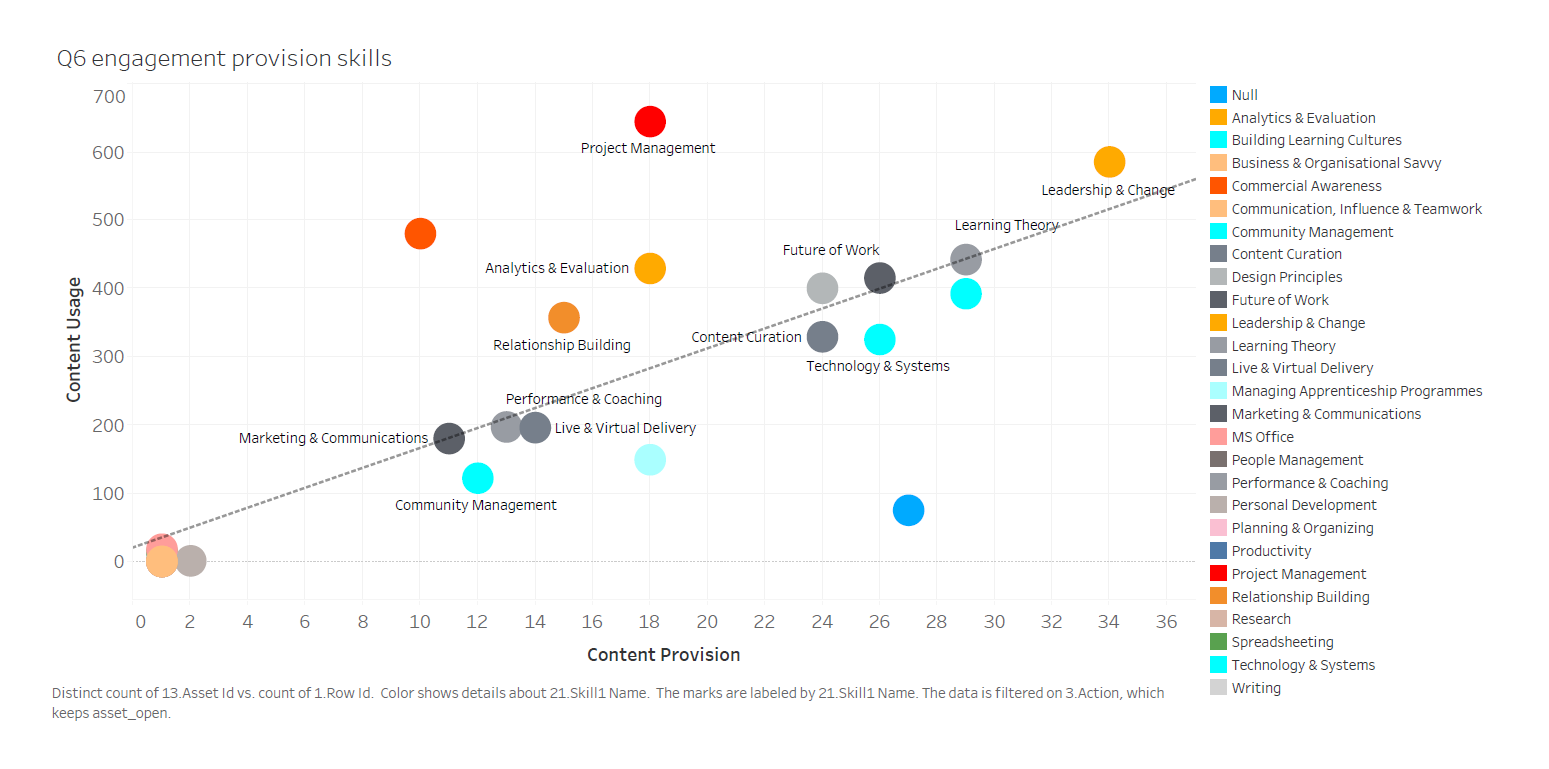
Clearly, this organisation needs greater content provision around project management. And you can extend this kind of analysis to cover things like content providers to really discover which content is delivering return on investment. That’s the value of a data-driven learning strategy.

7) Trapping users in bubbles
One of the potential limitations of AI is that, if it’s not set up carefully, it can get virtual tunnel vision. It sees a user likes a certain niche of content, shows them more of that same content, notices they inevitably consume more of it and then serves them up more in a feedback loop. This can lead users down a narrow path that they can’t escape from, and is the same kind of shallow recommendation that keeps Amazon recommending you toilet seats for weeks after you purchase one.
The frequency and strength of this user bubble vortex depends on how well your machine learning is set up and the depth of your recommendations, as well as the variety of data points taken into consideration. However, there will always inevitably be this kind of drag in any system where recommendations are based on similarity. That’s why it’s important to build an element of randomisation into your algorithms. For example, occasionally suggest a piece of content which may not be the optimal match - a bit of a left field choice. This gives users the chance to break free from the bubble and engage with a variety of content.
8) Failing to optimise processing time
We’re all so used to the well-optimised algorithms and vast data centers that process our everyday searches and browses that we tend to forget all the behind-the-scenes heavy lifting that goes on. Google alone uses enough energy to continuously power 200,000 homes. If we want our own users to enjoy the same level of smooth user experience, it’s something that we can’t afford to ignore. The sheer amount of calculations that take place to bring users machine learning-led recommendations require strenuous optimisation to avoid long loading times that ruin UX.
You need to optimise your algorithms to serve content at the pace the user needs it. Our data science team are always on top of optimising this for magpie, balancing data processing bandwidth and the relative processing cost and optimising that against the demands of the product even as we scale users, skills and content.
9) Not valuing the privacy and consent of employees
Smoothly optimised processing is the bedrock to a great user experience, but there are other more holistic factors that can affect user engagement when you’re processing their data at scale. In the age of GDPR, people are far more aware of the value of their data and less keen to give it away, especially something as revealing as which of their skills they feel are underdeveloped.
Put together a set of data principles that guide how you’ll take care of users’ data and then, most importantly, communicate those data principles to your team so that they feel emboldened and encouraged to use your platform as a safe space.
10) Not upskilling your team
Most of the points so far have covered the AI itself, the machine learning and algorithms that power your data-driven learning provision. However, that machine can only do so much on its own. Guiding, tinkering and optimising it along its way will be your human team, so you need to make sure they’re equipped with skills they need to turn good to great. Yet the majority of L&D teams say they ‘cannot use data effectively due to L&D lacking in-house data skills’.
.png?width=149&name=The%20ultimate%20upskilling%20cheat%20sheet%202021).png)
The Ultimate Upskilling Cheat Sheet for 2021:
Get practical bite-sized advice to succeed in upskilling your workforce.
Encourage your team to sign up for a data science course or bring in some data science experts, whether as external consultants or through hiring. Only 10% of L&D teams are working with data specialists, so it’s a real differentiator.
Hopefully, you’re not too daunted by the list above. Bringing AI into your organisation can have transformative effects, ones that only continue to multiply as the technology behind it improves. Start small, keep the above list in mind and don’t be afraid to ask for help and you could soon be getting ahead of the pack and delivering real value to your organisation.