Machine learning algorithms learn from experience to improve their performance at certain tasks. While working for a company that uses machine learning in its product, Filtered LXP, I’ve learned a bit about the truths behind what can seem like machine learning’s magical ability to mimic or exceed human performance in certain tasks. When evaluating any system that claims to use machine learning, there are three realities you can bring to bear on it:
1. Firstly, applying machine learning to do stuff on top of existing (legacy) platforms is fraught with problems. Usually the data isn’t set up right for machine learning or isn’t aligned with the task that it’s claimed the machine learning performs. A good example of this would be trying to apply machine learning to LMS data for the purpose of making skills-based recommendations. If your LMS is mostly used for compliance, the resulting machine learning-made recommendations will reflect that fact and feel like compliance as well, since that’s all the data knows. In short, if the system is not full of data designed to be pertinent to the task the machine learning is purportedly doing, it’s unlikely to be a good use for machine learning.
2. Secondly, to perform a task usually done by humans with machine learning with no pertinent data for the machine to learn from, you will need a minimum viable product which automates that task - but without requiring machine learning - in order to generate the feedback data to allow your machine learning to get to work. In other words, there’s often a cold start problem with machine learning (which is why around the world there are thousands of people now employed in tagging data to make it useful for machine learning systems). In the case of Filtered, we overcame the cold start problem by starting with a rules-based system that generated the kind of feedback we needed (relevance, usefulness) on top of skills-based learning recommendations. Only then could we apply machine learning to the dataset.
3. Finally, if your machine learning system does not improve its performance at the task, then there’s no point in it. That’s the difference between rules-based and machine learning. Rules-based systems only get better by being manually changed. Machine learning systems, within certain parameters, get better at that task as more feedback data is added.
So how do you know if any system is legitimately machine learning or not? Well, the first two things are warning signs but they don't necessarily mean that the system isn't applying machine learning.
But the third one is less ambiguous: does the system fit the definition, does it learn from experience and get better? If the task itself is recognisable to a human, humans can evaluate its performance at that task over time via ratings.
In Filtered humans do this inside the platform. The resulting data shows us that, yes, our recommendations do improve with time. Our machine is learning.
Here's how we know. Every time a user of Filtered receives a recommendation they mark it ‘That was useful’, ‘I knew this already’ or ‘That wasn’t relevant’. If users don’t mark things not relevant, we know it was relevant. If they mark it useful, even better: the recommendation worked.
Here is how our algorithm performs in terms of usefulness for users over time:
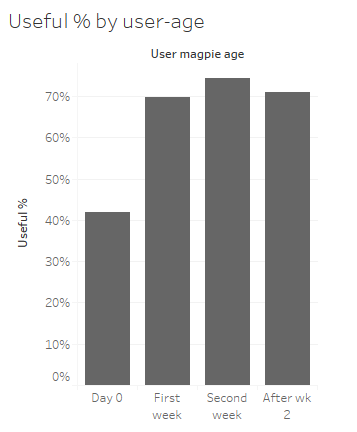
This data comes from all Filtered users over all time, up to March. The percentage of assets marked ‘useful’ by users increased from just above 40% on the first day they used the system to 70% after just one week of usage and then stayed up there. We see similar findings across most individual client instances of Filtered.
We still have lots to learn about this improvement: the factors playing into it and how we improve that % beyond 70%. But this is how we can prove Filtered gets better at its task of making useful recommendations with individual usage.
Many learning systems now claim to have machine learning in them that makes recommendations. So let me know, how does your system measure the usefulness of those recommendations? Can you prove your machine learning is learning?