Making calculations to understand the words underpinning learning content is what we do. We do that in order to improve the metadata for and decisions about learning content. We are therefore naturally — along with the rest of the world — rather taken with the developments of large language models (LLMs) and Chat GPT in particular.
The hype is real, whatever else is. ChatGPT achieved one million users within five days of its launch in November last year. It reached 100 million users just two months later, making it the fastest-growing consumer app ever. Over the first few months of this year, more people searched for the term 'ChatGPT' than they did 'Taylor Swift'. Everyone’s talking about it, reading about it, writing about it. And we’re using it to help us read and write.
Handily for us at Filtered, this surprisingly sudden mass adoption of generative AI has helped with a major element of our mission: to explain what concepts like neural nets, natural language processing, LLMs are and what their benefits might be. It’s also stirred up (constructive and otherwise) debate about where this technology might take us.
Awareness has been achieved, then, emphatically. But the subject is so hotly contested that it’s hard to find a true signal. I wrote a HBR article with Marc Ramos about how to choose the right generative AI project by considering risk vs demand, which may help in some situations. To assist further, I wanted to write about Filtered’s move in this area which we believe is specific, thought-through, realistic and valuable. It may bring some signal for you amidst the chatGPT cacophony out there.
Filtered & AI
We’ve worked on the intersection of AI and learning for a long time (since around the time OpenAI was founded in fact — 2015).
Our product was an adaptive course. We created a rules-based algorithm to take answers from a diagnostic to filter out parts of a course, leaving users with a shorter, more relevant, more impactful course. We — and my co-Founder Chris Littlewood in particular — achieved a US patent for the algorithm. There are precious few of these in L&D.
Our second product was an intelligent recommender system, called magpie. That took information from a user’s profile, along with user behaviour data to calculate a match between a user’s skill profile and a skill profile for each and every learning asset. When the match was good, a recommendation was made.
Finally, we took all of that thinking and used it to create the Content Intelligence category. People at corporates are drenched and drowning in a sea of content. We describe the problem as Content Chaos. We run multiple black- (neural net, opaque) and white-box (explicitly calculated and transparent) algorithms to compute a numerical value between zero and 1.000 for any piece of learning which indicates how much it is about a particular skill, concept, behaviour, value, etc. That helps our customers buy, curate and tag better.
We’ve ruminated on AI & learning for a decade. There’s an opportunity for L&D and for us to capitalise on the ChatGPT hype. How?
L&D may be slow to take it up
It would not be the first time that technology makes a slow path to L&D. We still use SCORM and other antiquated methods. Incumbent, inflexible tech stacks combined with a very conservative attitude to risk from IT will be hurdles that even ChatGPT can’t talk its way around. HR technology uses and generates sensitive HR data and that is a real risk for people and privacy. And there’s limited facility within a neural net to scrutinise output.
The so-called hallucinations and misinformation from LLMs do not help. Though the hallucinations are rare, they can be shared fast and loom large in the minds of risk-averse decision-makers at companies with hard-won reputations. Noone wants to be responsible for an embarrassing, egregious error. Noone gets fired for buying IBM.
Somehow, the application will need to be both in high demand and of low risk. We, at Filtered, are focused on just such an application…
…Intent
An application that does make sense right away is to use the conversation to help a user discover their intent. By user, I mean anyone working in L&D supporting learning initiatives in some way. And by discovering their intent, I mean that intent is often not clear to us working in the industry. We might be interested in teamwork, say. But that’s only a top-level domain. If we really pushed ourselves (or we leant on AI to help us) we might discover that what we’re really after is effective communication, conflict resolution, building trust, team leadership, team building, remote teamwork or something else. Indeed, we might want to delve a level or two deeper even than those.
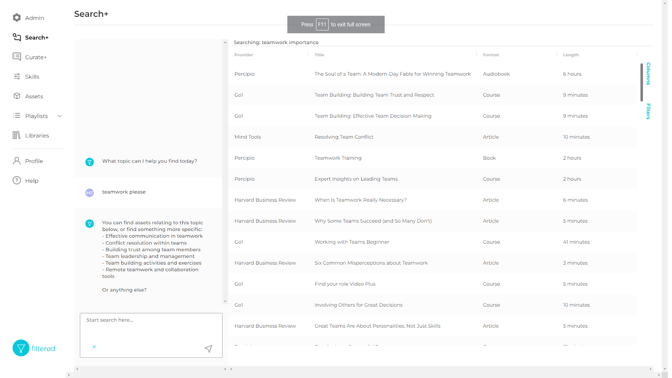
As the intent crystalises, becoming more granular in the process, Filtered’s algorithms use this to refine the selection of content from your pool of learning (the right-hand panel in the screenshot below):
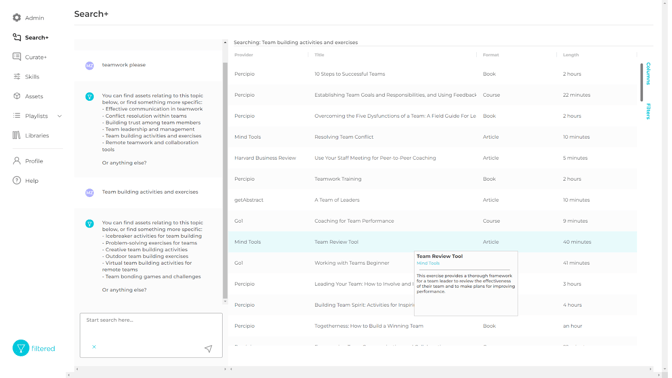
Demand for this is high. Thousands of curators and people with curation responsibilities are searching for individual assets and creating pathways and playlists every hour of every day. But the process is largely manual, imprecise and tedious. Filtered+ solves all of these issues enabling highly granular search, tagging and curation of highly granular results for the underlying intents. We frequently hear customers say that search in learning systems is 'basic' or 'broken'. By marrying granular intent (leveraging GPT4) with highly granular search and curation (Filtered+), the problem of discovery substantially solved.
And risk for this is low. The tangible output of Filtered+ is a learning asset or a learning pathway, generated exclusively from your own pool of learning content (internally produced or externally procured). So it’s an entirely on-rails deliverable. The worst that could possibly happen is that a less relevant asset is suggested and this is extremely rare.
I expect that there will be many rapidly-assembled applications of LLMs over the coming weeks and months. I encourage you to evaluate them in terms of demand and risk. And if some of the above appeals, book a meeting with our team.