This presentation originally appeared at our data-driven strategy workshop, Taking Flight.

- Recommendations are really, really important.
- 'Recommendations are Queen' is a reference to Bill Gate’s line, the title of a paper he wrote in 1996: Content is King and more specifically, in the first line: 'Content is where I expect much of the real money will be made on the Internet, just as it was in broadcasting.' Now that the content prophecy has played out, to the point where it’s now very hard to make money with content – the publishers have had a very rough decade – getting people to the right content has become the new priority.
- We use the abbreviation ‘rex’ for recommendations because… recommendations is 15 letters and it messes up slides.
- The image in this slide is subtle but it’s of Fool’s Mate in chess - the only way a game can end after 2 moves. White loses and checkmate is delivered by the black queen on the square h4.
.png?width=1280&name=190729%20Taking%20Flight%20v.Article.pptx%20(1).png)
- The thing we’re trying to do, really, is something almost all of us do multiple times a day.
- To read, watch or listen to some content and as we do to perform a series of calculations to assess that piece of content for relevance to hundreds of people we know, taking into account the individual characteristics of those people as we do it and decide if something’s relevant and for whom and why. Without even meaning to.
- This is a pretty amazing feat. Stupefying.
- And we do this a lot. We share billions of pieces of content each year. 38% of content that’s shared online is either educational or informational. We don’t just share gossip and photos and memes (admittedly we do that a lot too - 62%).
- The technology we’ve built and continue to build - which is called content intelligence - codifies this very human activity, makes it better, and makes it scale.
- I’m going to offer 4 perspectives on recommendations and just hope you find them intriguing.

The first perspective is to just look at how the tech giants solve discovery. They do this in four important ways…
One is search, obviously. And here are four big, essentially tech companies doing that very effectively: Google, Shazam, LinkedIn and Amazon.
Second is filtering (great verb).
- Then you have companies that rely on a browse-first UX. This is inefficient but sometimes the process of engaging e.g. swiping left is fun in itself, so mostly-browse is OK or even preferable..
- Of course, Tinder actually has prioritisation algorithms running in the background too.

Finally, we have recommendations aka personalisation aka content prioritisation. Social media is essentially massive-scale content prioritisation.

There’s an important difference as you go from left to right which is how much the user knows.

- Filter and browse kind of detract from the insight here.
- Really there’s a dichotomy here between Search (user has a clear idea of content she’s after) and Rex (user doesn’t have a clear idea).

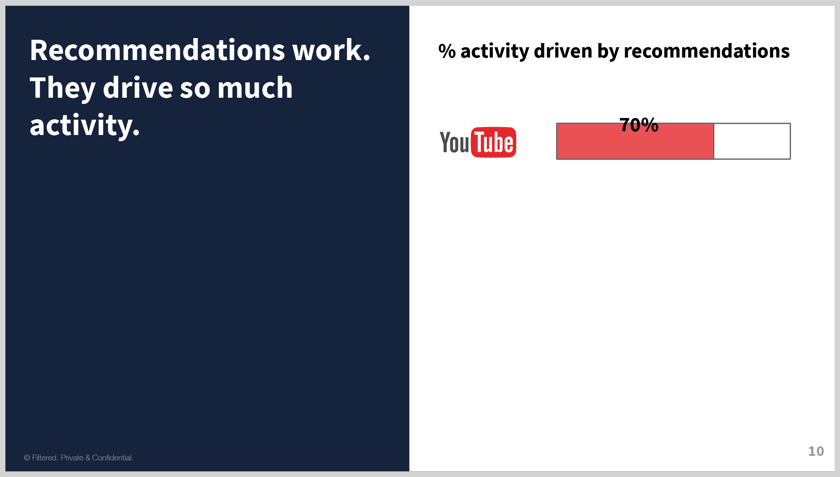
- You can even quantify how much recommendations are playing a part with some of these providers
- For example, YouTube…
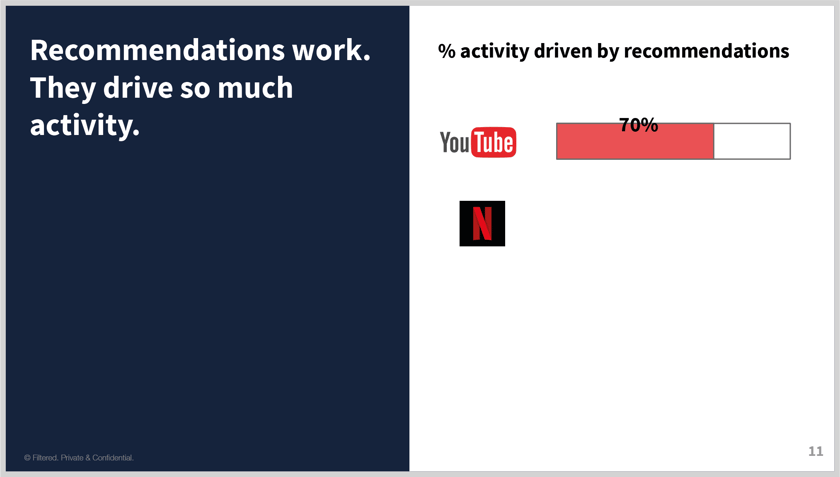
What about Netflix? Higher or lower?
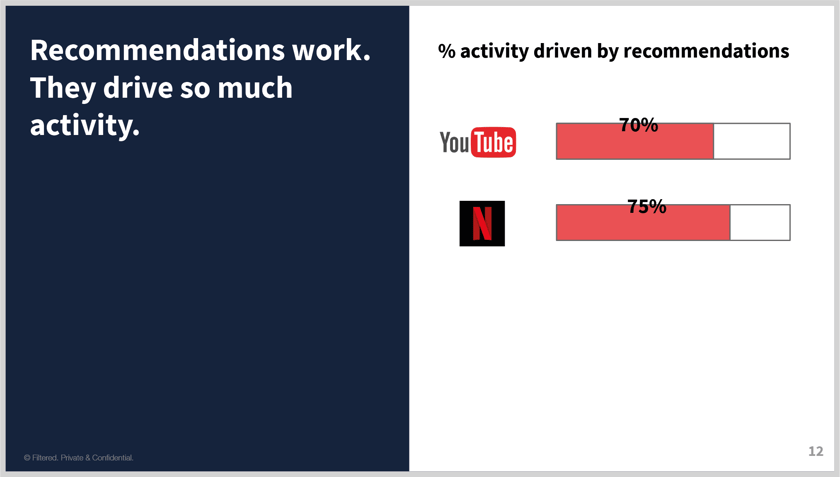
A bit higher.
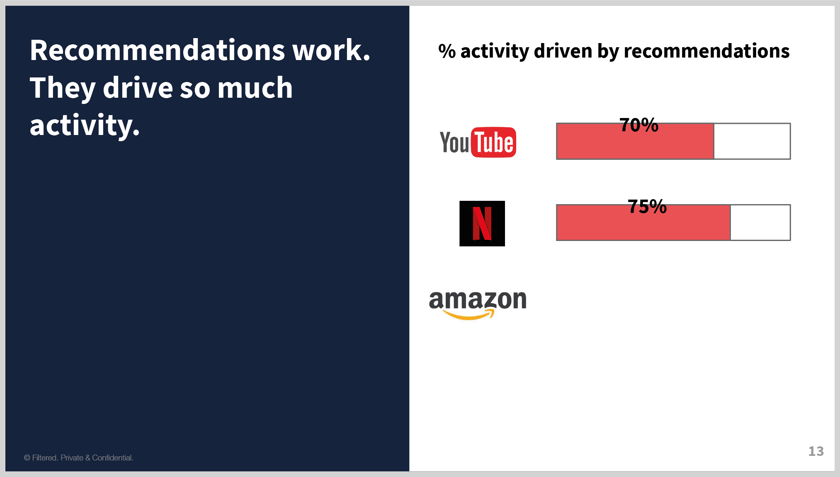
And Amazon – higher or lower?
.png?width=1280&name=190729%20Taking%20Flight%20v.Article.pptx%20(14).png)
- Lower.
- This is McKinsey analysis (references at end).
- But it surprised me that it was even as high as 35%. But then you think about the items that come with items you buy – clusters of items that you didn’t initially know you need to optimise function / enjoyment of the product, it starts to make sense.
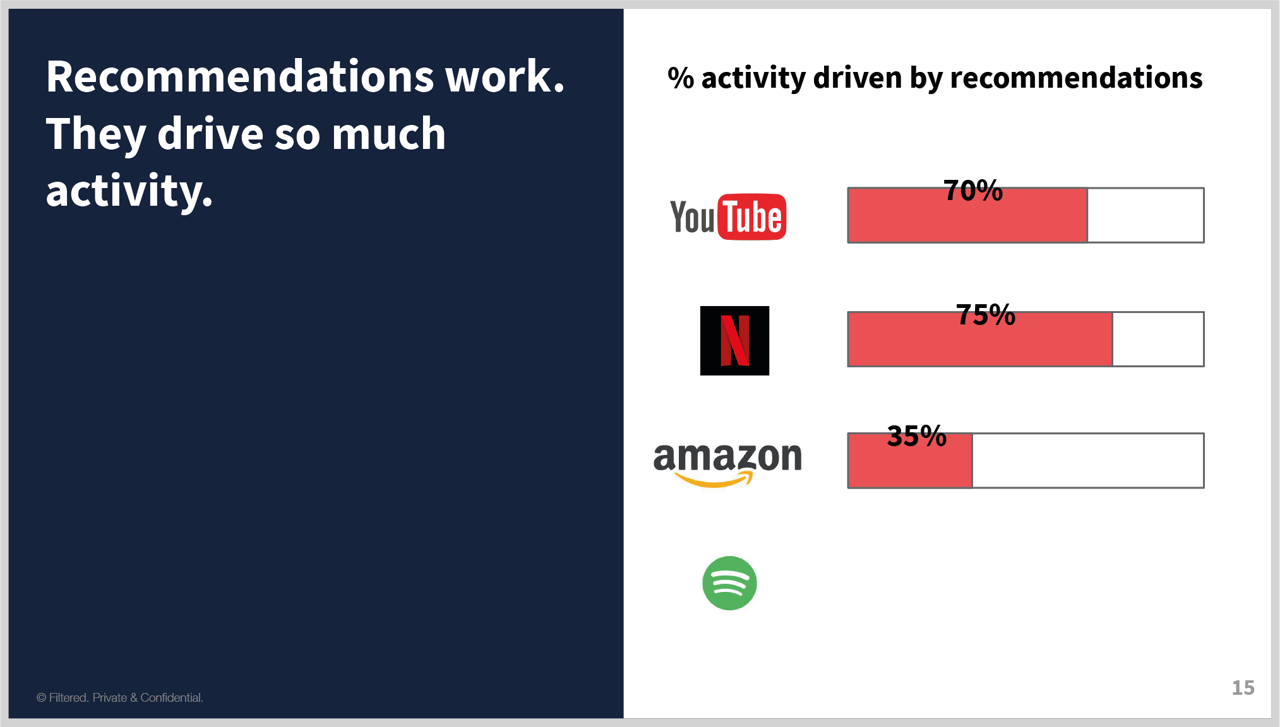
- And what about Spotify – higher or lower?
- This is actually another trick question…
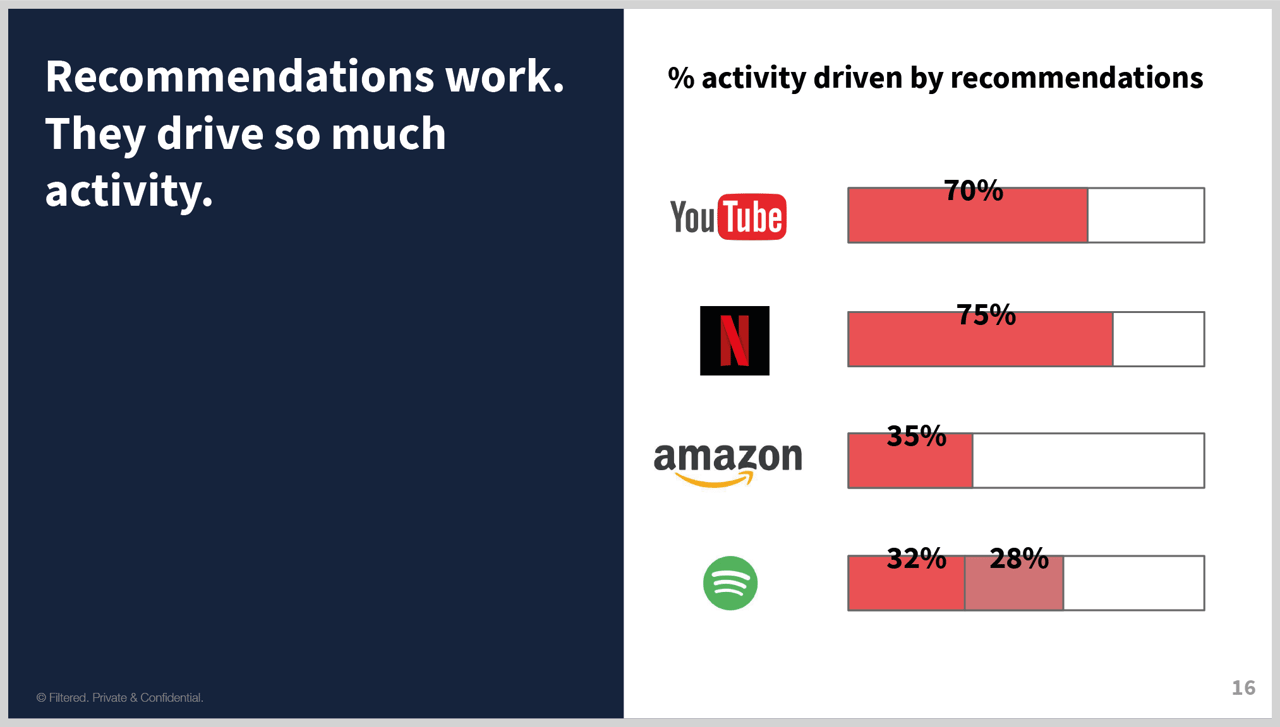
- …because 32% of activity is from playlists, generated algorithmically from listening habits.
- But then a further 28% listen to playlists based on genres or moods – also algorithmically generated.
- Combined, this is 60%.

- The point is that all these tech companies have developed software that influences the behaviour of billions of people everyday.
- There must be lessons there.
- I’m not sure what the stat should be for L&D. But I suspect that if we optimise what we’re doing, it would be higher than whatever the current number is.

- The second perspective is that the unknown unknowns is massive.
- Let’s run through a 2x2…

- First, there’s the known-knowns - what’s easily accessible in your head.

- Then bottom left is the stuff you have in your head somewhere but without much awareness. I’m no expert here but think hypnosis.

- Then there are the known unknowns. In L&D we often call this performance support.
- That thing, I need right then and I know already and search for and find and then…I’m OK.

- Bottom right is the vast unknown unknowns which we address through pure chance (stumbling upon)…
- …or algorithmic recommendations.
- So in a sense google have been solving the small problem (top-right box).
- The bigger problem is proactive, unprompted recommendations of content you didn’t know you needed.

- In the case of algorithmic recommendations the AI debate isn’t about when.
- It happened this century already, with a lot of progress in the last 10 years.
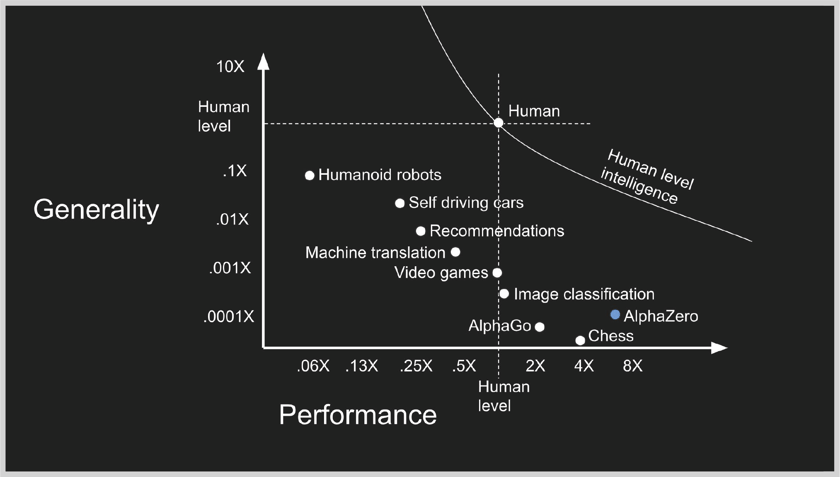
- Here’s a slide from Google.
- I love it because it puts a parliament of AI use cases together and gives you a sense of how impressive they are.
- The Y axis is about the generality of a task, relative to humans.
- The X axis is the performance of AI, again, relative to humans.
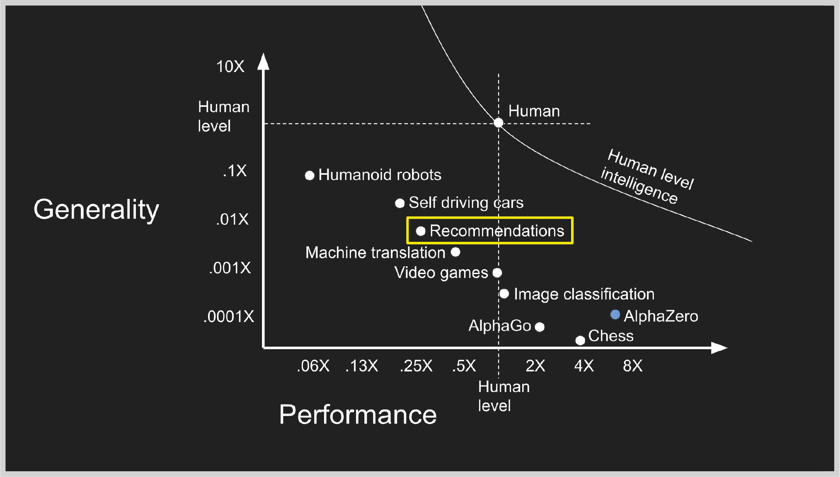
- And there’s recommendations, conveniently fitting the curve
- But there’s something wrong. Recommender systems actually work much better than the best human could possibly perform. Think about that.
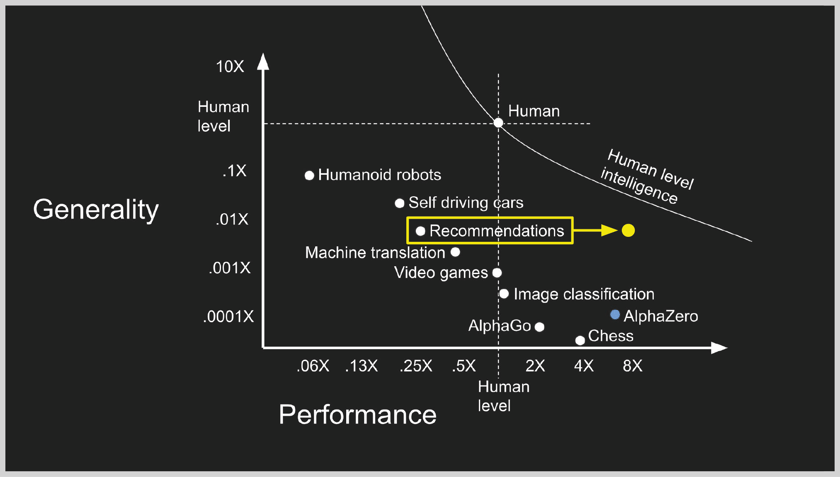
- So the yellow dot should really be over to the right.
- I think this is just clear and that google’s wrong. One of the reasons this might get overlooked is that it’s so very difficult to measure the quality of recommendations.
- The other stuff on here is easier to measure, compare and quantify eg road traffic accidents / speed of journey, results of chess games, video game scores, etc.
- 4th perspective: step-by-step inductive reasoning.
- As we go through this, notice at what point - if at all - you disagree.
- I don’t think we’ll lose many people here!
- We tend to think of the content in terms of these three classes:
- Your own material on SharePoint, intranet, extranet, LMS, Dropbox, etc
- External libraries eg MOOCs (10k), Udemy (140k), Pluralsight (15k), LinkedIn Learning (20k), Get Abstract (19k), etc, TED (4k)
- Many companies are having to deal with ridiculous numbers like a million assets. An actual million!
- Maybe it’s less than 1%.
- Of course, it depends on what you mean by excellent obviously. But it’s something like: up-to-date, not obsolete, well-tagged, impactful, business-aligned, attractive, original, persuasive.
- Let’s say it is 1%. Well if you start with a million, that’s still 10,000 high-quality assets in your system.
- And you’re going to start with a million and end with a few thousand, whatever company you are... because of the the internet.
- So what’s a busy worker going to do with many thousands of assets?
- …not use it, for the most part.
- We spend just 1% of our work lives learning formally, according to the now fabled research by Bersin by Deloitte.
- We don’t even need the research to tell us this: we all know that the urgency of work trumps the luxury of learning
- Countless assets never see the light of day. If you were literally trying to hide them they would not be more hidden, with folders upon folders of slightly meaningless, official sounding corporate nomenclature.

aka an undiscoverability problem

- See first 25 slides above
- So it will happen here in L&D.
- It’s just really a case of how fast we make it happen.

- Stay in touch with me if you like.
- Thank you!