Two roads diverged in a wood, and I—
I took the one less traveled by,
And that has made all the difference.
— Robert Frost
TL;DR: many thousands of pieces of content have accumulated on every corporate system in the world. They cost lots and help little. Shrewdly configured algorithms - specifically, ours - can now reliably and scalably determine the quality and relevance of each piece of learning content, and enable you to make smarter, data-backed business decisions about what you pay for and put in front of your workforce. Pioneers are invited to test this with us.
You have a content problem, along with everyone else.
That problem is known by many names: Content proliferation; Buridan's ass; Choice theory; Hick's law; Information overload; Curation; Choice Overload; Overchoice; The Paradox of Choice; Content saturation; too-muchness.
The problem is expressed in many ways - the following are all actual or typical quotes from the industry: “we're just throwing content into a platform and hoping for the best”; “we have resources on SharePoint, our LXP, several LMSs and the whole thing is a mess, frankly”; “I type in ‘Agile’ and get back utter rubbish - and lots of it”; “people are overwhelmed by all the content...it’s like we’re spinning them around in the library and telling them to choose a book”; “‘There’s so much content we can’t find anything”; “most of this content is pollution”.
The problem has several undignified characteristics:
- People consider the content they see to be poor. So much can go wrong here, and usually does: it’s dry and dull; it’s stilted; it’s too basic, even patronising; it’s inefficient; it’s not relevant to their role or industry.
- People don’t discover content effectively. They encounter duplicate material and obsolete material. There are broken links. They find too much content and are overwhelmed. They don’t find any content for their purpose whatsoever. People find it hard not to make unfavourable comparisons with the enticing, rich experiences they enjoy as consumers of music, video, film, etc. The worst and most common problem is that they don’t even come to your learning system to learn at all.
- People miss out on the great stuff. For the right person, at the right time, the right content can be uplifting and inspiring, and change habits, outlooks, productivity and feeling of self-worth. But these encounters are lamentably rare.
- L&D and business functions waste money on content purchases. Companies pay six (and in some cases seven) figure sums for content which goes largely unused, unappreciated and without adding value to individuals or the firm.
- The large morass of content lacks purpose.
- L&D end up performing lower-level tasks than they should. For example, with so much data, L&D practitioners spend time labelling content manually, but even when there’s a team of dedicated content managers and major expense thrown at this, they never catch up with the mountains of content churned out every day.
It’s worth thinking of this as an off- or pre-platform issue. However good your LXP or LMS or NGLE, its effectiveness is obviously severely hampered if it’s populated with lots of mediocre and downright poor content. (Note that there’s a pre-content issue: skills - you can’t choose your content properly before you’ve identified the high-value skills. And there’s a pre-skills issue: the intended business change - you can’t choose your skills before you’ve understood the firm’s business priorities).

Abundance, quality, relevance & data
It’s not information overload. It’s filter failure.
— Clay Shirky
Of course, the content problem is not the entire problem with workplace learning. There’s technology and culture too. Culture is about people, habits, values and behaviours; technology is about the tools and platforms and their features and UX. This article is exclusively about Content. And the content problem is really about the abundance, quality and relevance of content, and the corresponding lack of data. I’ll say a few things about each of those.
- Abundance. Every single company has accrued many, many thousands of resources, materials, and pieces of content, and they are scattered around its various corporate systems. Each content library itself has thousands or tens of thousands of assets, and most companies that we speak to have purchased multiple libraries. Then there’s the content L&D or business functions or individuals have produced themselves - proprietary material. This comes in various forms - pdfs, videos, Word documents, Excel spreadsheets, PowerPoint decks, etc - and sits in multiple locations: SharePoint, emails, Teams, LMSs, instruments and extranets. And then there’s the web. Two billion blogs and articles have been published already this year and although a small fraction of those will be relevant for your workforce, there’s plenty that will be. And then there’s all the thinking, writing, recording that went on online before 2020!
- Quality. Quality is a difficult, partly-subjective concept made up of: impact, usefulness, provider reputation, breadth of coverage, depth of thought, and societal factors.
- Relevance. Relevance is also a complex and partly-subjective concept which: includes being for-a-particular purpose; relates to high-priority skills and topics; makes provision for preferences for different formats, lengths and levels; takes into account a planned future state for the firm - being future-proofed.
- Data. And metadata. Content data for learning is hard to come by. In L&D, we are not spoilt with massive usage data as the always-on, addictive platforms (Spotify, YouTube, Twitter, Insta) are. Consider this important, unheralded metric: data-per-learning-asset (DPLA). Most assets in most companies are untouched. This means the question of whether to remove, let be or promote assets goes unanswered. So the agglomeration of assets grows ever larger, ever more abundant, and ever less purposeful. For most people in L&D, the aspiration to make data-backed decisions is closer to a dream than reality.
Algorithms can solve this - today
In a world deluged by irrelevant information, clarity is power.
— Yuval Noah Harari
Algorithms – carefully steered by humans – can now solve almost all of this. Specifically, we have solved it. The family of algorithms and methodologies we have developed process the data associated with a given piece of content and robustly classify it. They can run through entire libraries of content in seconds to rank all assets for relevance and quality for a given skill or topic.
Let’s say one of your high-value skills is ‘curiosity’. We’d work to better understand what you and your organisation mean (how close is it to growth mindset, innovation, ideation, creativity…?) We’d then run various algorithms with different degrees of human influence to produce output that looks like this:
-1.webp?width=600&name=2020-09-22%20(10)-1.webp)
Here we have - for 'curiosity' for a particular firm - an ordered and numerically-scored list of the relevant assets from a large pool (in this case, it’s an assortment of 40,000). The algorithms calculate a score for relevance as well as for quality for each and every single asset. We manually validate and calibrate the confidence scores for Relevance and Quality (on the right-hand side) with expert human judgement. So 0.700 means that if we selected 10 such assets with that confidence score, we’d expect seven to be classified correctly as judged by a human subject matter expert. This is not merely a log of content. It’s a dynamically ordered list that is recalculated for each skill at each firm and constantly refreshed as priorities change and new content comes into play.

Imagine these outputs for precisely the content you have and for each of the skills your organisation has prioritised in your skills framework. It would provide the data to make data-backed decisions to remove, add and promote content based on its relevance and quality. In particular, moving to a smaller, more intentional pool of less content is a philosophy we hold and recommendation we make. It would enable you to launch campaigns based on demonstrably relevant, priority content. It could be used to construct learning pathways in your LXP. It could be used to fuel intelligent learning recommendations. It can support a build a business case for your learning strategy.
Strategy is about making choices, trade-offs. It’s about deliberately choosing to be different.
— Michael Porter
When we aggregate these results by provider we see even greater benefits: we can start to see how useful your content sources are for you, relative to your high-value skills. You can even put the costs in and work out another vital but overlooked metric in L&D: Cost Per Qualifying Asset (CPQA) - see below (numbers here illustrative only).
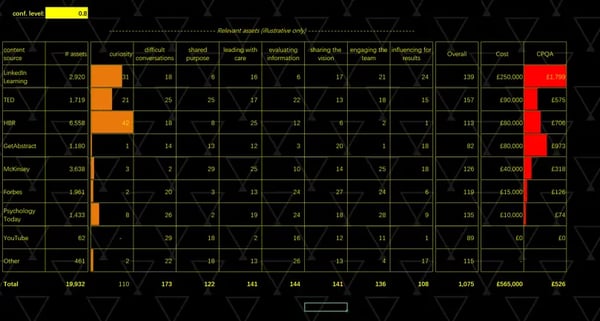
You might use this data, including the CPQA, to compare the relevance and value for money of sources of content you have with each other. You might also want to compare them with content you don’t have, including the web. Can some adjustments be made? Might this help with a contract renewal negotiation? Can you use this to persuade your preferred content provider to produce more for Skill X or Topic Y? Or maybe you need to produce that yourselves. Or maybe you don’t have many gaps at all. The point is that you learn where the areas of under- and over-provision are - we can show you a heatmap. We have clients that have saved one-third of their content spend in this way.
Another benefit is simply the level of engagement with algorithms. Because we take multiple approaches (human-only, rule-based calculations, neural networks), we’re able to triangulate and explain what’s going on. We can peek inside the black box and discuss it with you. It’s high time that AI vendors did a better job of explaining their dark art.
But can we trust these results?
Now we have a means of generating meaningful data for our learning content and this is a major step in the right direction. But how can we be sure it’s reliable?
We’ve spent a lot of time thinking about how to validate it, for ourselves and to the market. Some early work we did was written about in Scientific American. Since then, we’ve developed some other validations.
The most obvious and simple of these is to just have a human ‘mark’ the work of the algorithms. You feed the algorithms the content and tags, they produce the output, and a human subject matter expert agrees or disagrees, line by line.
The other method is to calculate the F1 score for an algorithm’s performance. This is a statistical measure of how thoroughly (technical term: recall) and how precisely (technical term: precision) an algorithm has classified (tagged, labelled) a set of content. This is a little more involved and requires having a separate set of tags that you can trust as ‘ground truth’ (this is far from trivial but we can help).
To be satisfied that algorithms are passing some kind of important test, we need to set a pass-mark. Well, the standard set by an expert human gives us an important, useful benchmark. If the algorithms can come reasonably close to this in terms of accuracy, then we’re probably in business, as processing time will likely be orders of magnitude quicker (and cheaper).
An alternative and intriguing method is a modified Turing Test, to compare several technologies and methodologies against each other. Each would receive some inputs and produce outputs. A panel of human judges - acting independently - would receive these outputs and try to decide whether a human or a machine produced them. The winning solution will be the one that has fooled the most judges. AI claims in L&D are now as common as claims about ROI and learning culture. Yet many learning systems - particularly LXPs - are bought ‘for the AI’ and buyers are frequently left underwhelmed; as an industry we must try to change those impressions with more tangible demonstrations and proofs. So it would be interesting to put all these providers to the classic test from computer science and see definitively (and publicly!): who has the fairest algorithm of them all?
We’re satisfied that we have achieved human-level performance on the measures above (and we invite you to put this to the test - see below). Of course, that’s not to say that there’s no more work to do algorithmically or manually. On the algorithmic side, there’s plenty of nuance to ‘achieving human-level performance’ eg for some skills algorithms can outperform humans and for some they fall short; we need to strive to increase the gains and reduce the lags. And there will always be an important strand of manual, human work. For example, curating learning for factors like diversity (in its various forms) is a subtle art which should not be handed over just yet to algorithms (and handled with great care by the people who accept this responsibility).

How it works
If you want to investigate this with us, these are the steps:
- We have a conversation about your priorities - skills, behaviours, values, upcoming campaigns.
- You send over some sample content data.
- We run our algos over that content to produce asset- and library-level results.
- We discuss these results (a process of questioning, validation, assumption checking).
- We agree a cadence for running this analysis (weekly/monthly/quarterly).
We like to have interesting conversations and offer to conduct an analysis as described above (on a sample of data) for free for people from firms that are serious about changing the status quo. That status quo is mountains of low-grade content without the sense of purpose or quality of data to sort it out. We’re looking for pioneering problem solvers who are interested in working out which content is really important for their workforce. Drop your email in here if that sounds like you:
Postscript: a personal note
We started the business in order to get people to the right learning content, initially with Excel. We felt that for the most part, people see very little content that makes a big difference to their contribution and confidence at work.
But the reason I care goes somewhat beyond this. It’s also about the practice and impact of content in L&D and in general. The world produces more and more without much of a care for what there already is. Efforts therefore rarely build on existing efforts. In many cases, the newer offerings are of lesser quality (even accounting for kids-these-days fallacy).
Here’s an example. Gladys Sanders (no relation!) wrote a piece in The New York Times in 1979 called A Time to Look Beyond Eye Contact. I think it’s a very good article, suggesting the somewhat contrarian view, especially at the time, that not making eye contact is perfectly OK. Today, if you google ‘should i make eye contact’, you get 2.4 billion results, at the top of which is this sage advice:.webp?width=634&name=ezgif.com-gif-maker%20(1).webp)
This suggests to me that we have not used the last 40 years very well, to collaboratively build on excellent contributions from the past. And it’s such a shame because the web should enable us to build content collaboratively.
But I believe it is possible to build. Here’s an example from my own work which may seem self-aggrandizing, but I include it just because I think it’s apt and instructive.
A couple of years ago, I wrote an article in Harvard Business Review about Timeboxing. It’s been popular there (and even more popular, more recently, on TikTok - see below). The first sentence is a reference to a previous HBR piece, by Daniel Markovitz, which opened my eyes to the practice and has influenced my thinking. I then try to take that thinking forward in a few ways and Daniel was in touch to say just this after it was published.
@debbbag how i stay productive! ##productivity ##hacks ##procrastination ##foryou ##foryoupage ##fyp ##harvard ##tiktokartists ##timemanagement
♬ She Share Story (for Vlog) - 夕依
The relentless, heedless creation of content is a chronic waste of time for creators and consumers alike. But if we can combine our expertise in learning with shrewdly configured algorithms to rake through the content, filter it, organise it, and prioritise it for the right users, and build on top of this, mindfully and purposefully...we do a great service for humankind.
It is the ability to choose which makes us human.
— Madelaine L’Engle