We recently asked 100+ L&D professionals how they would approach solving the gargantuan task of combing through 4000+ search results, and we weren't disappointed. Read on to see what approaches your colleagues would take.
This problem is what many of you - and our customers - are faced with on a daily basis.
You are responsible for learning systems* that promise a one-stop-solution (shivers) for all learning content… like, EVERYTHING.
But there is not a single technology in the world that has actually nailed managing this. There are currently two popular solutions to this in L&D:
-
Search
-
Recommendations
Search - if Google can do it, why can’t we?
Well for starters, Google’s positioning is unique. No one can come as close in the enterprise world. And those user behaviours are so well engrained.
Whether we like it or not the majority of people implicitly trust Google, can get what they need from the first few results and these results come in at an instant from billions of pages. This is unmatchable.
This then creates the deep disappointment of many enterprise users: search is simply not ‘good enough’ or should be 'more like Google'. Not. Gonna. Happen.
Recommendations - if Netflix, Spotify and Amazon can, why can’t we?
It’s easy - use AI and machine learning to bubble up the best content.
It’s the opposite to search in some ways, it relies on the system understanding both sides (content and user) to provide a great match (think online dating!).
Again, large consumer-driven tech such as these have piled in $$$ billions. These amounts add up to multiples of what the L&D industry is worth - in total!
And even if L&D tech vendors could find decent AI or machine learning, they lack the billions of data points to make it effective, because so few people actually end up using it. Any data that might be useful is often stuck in other low-grade systems such as HRIS, LRS, email, development plans, communication channels etc.
Recommendations in L&D remain, for now, a holy grail.
But what if there was a third way?
What if there was a way in which you could find a meaningful and manageable way of dealing with such an enormous task such as dealing with 4,000+ results for Leadership content? And one that did NOT require spending $$$ thousands on a 'magic' bullet of overly smart tech?
It does, however, involve you and your L&D teams putting in some serious graft by taking on the role of gatekeeping the most precious and valuable information for YOUR organisation.
It requires putting your vast amounts of human intuition, knowledge and understanding to help search, find, sift and choose what you deem to be of value from the various sources of content available to you.
It requires you developing 💥 CURATION SUPERPOWERS. 👩🎤
Curation - the promised land.
What exactly is a curator?
"...a person who selects the best information found online with regard to its quality and relevance, aggregates it, linking to the original source of news, and provides context and analysis." - Federico Guerrini, Reuters Institute Fellow’s Paper
There are many different approaches to curation in L&D.
In fact, these are the results from some of L&D’s leading experts on how to solve exactly this problem (approx 50 ‘serious’ and viable options, although the non-serious answers are also pretty funny!):
Curate better 32%
-
Qualify the content Rebecca Bittner, Greenfield Learning Inc
-
Rank & rate the content
-
Limit to top X results Peter Manniche Riber, Novo Nordisk
-
Compare results vs usage Pragati Kamath
-
Go granular with your definitions: Marguerite Thibodeaux, Magnanimous Leadership
-
Order the results using the best data available
Improve discovery 28%
-
Deploy an automated smart metadata application Francesco Mantovani, P&G
-
Add more tags to the metadata Jackie Kirochfer, Docebo
-
Diversify & retag content Marek Hajduk, Novartis
-
Encourage people to search ‘better’ Gabe Gloege, CultivateMe
-
Fix your search tool and/or add more filters
Ask others 16%
-
Survey your workforce directly
-
Coaching (real-life) / ask a human
Delete & restart 14%
-
Delete it all and start afresh
Do nothing 10%
-
Randomly suggest content
-
Use Google
-
Do something poetic Thejaswini Unni
So what exactly should you do?
There’s clearly a strong preference to address the curation and discoverability issues from this audience; these are two sides of the same coin.
If you can improve the metadata in a smart, automated way then you simultaneously improve how well it bubbles up in search systems AND your own curation capabilities.
You have better and cleaner data to feed both the system and your own human judgments about what to filter in or filter out.
And then you curate judiciously! You must rely on the data that is available to you: usage, engagement, rankings or ratings, relevancy scores and so on.
Some of this will export easily from your LMS/LXP but some may require another system like Content Intelligence (yes, sorry, I'm biased, what can I say?!) to give you meaningful, trustworthy and accurate data.
What does this look like in real life?
Take just one of the most popular libraries out there - LinkedIn Learning. It has 700+ results itself for ‘leadership’.
Even this relatively small number is impossible for any end-user to make sense of:
But you’re missing ALL the other relevant content that might be useful.
So if you threw this all into Content Intelligence, you’d get in a snapshot a scan of all your content, by quality, by cost and coverage.
You could instantly evaluate what’s good, enhance the metadata with better tags, curate the best content and then create playlists to surface that content wherever you want.
Here’s a snapshot:
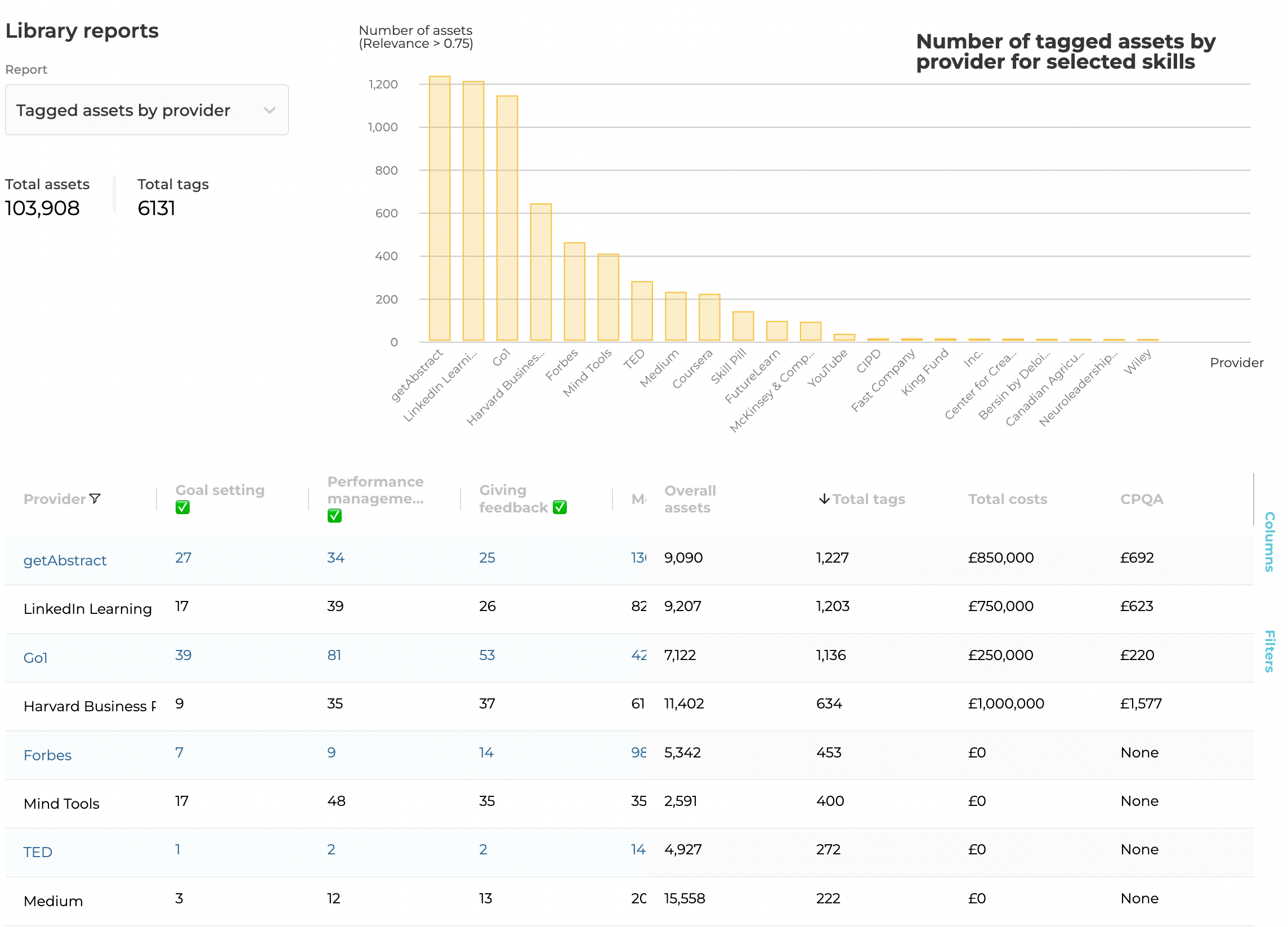
In this example report (figures are purely illustrative!) you can see that despite HBR and LinkedIn Learning showing some of the biggest libraries, and the most number of tagged assets, it’s actually a library like Go1 which ranks the cheapest for CPQA (Cost per Qualifying Asset).
This is one of the best measures of value that L&D operators can use as it’s a blend of cost and quality.
But this is only the tip of the CI iceberg. If you want to know and see more:

And if all else fails: “turn it off and on again!” - John Hincliffe, Jam Pan 🤣