Or, how Filtered became fixated on skills and content.
Wherefore Content Intelligence? Well, we couldn’t describe better why it was needed than the Josh Bersin Company’s Nehal Nangia in this blockbuster article. But only we know the true story of how we developed it. This story is about our fixation on the link between skills and content.
It started, like a million other products and ideas, with Excel. Specifically, a company named Excel with Business, the forerunner of Filtered, and now a successful brand of online spreadsheet training catering for consumers and small businesses.
The starting point, even then, was solving a skills/content problem.
Excel is big. You can do a million things with it on its vast gridded canvas of a million rows x 16k columns. To this day, Excel is one of the world’s most wanted skills. But really it’s a skill made up of many skills.
The basics are held in common, sure (formatting data, formulae). But beyond that? Macros. Visualising data. PivotTables. Decision making. Even business strategy. A project manager needs a different Excel to a marketing executive to an accountant to a student. How could one course cater for them all?
The key to solving this content problem was (yep, you guessed it) a good skills framework.
Filtered developed one of the world’s first Excel-specific skills frameworks (inspiring the current framework of long-time client ICAEW).
We then broke the endless mass of potential Excel training down into thousands of teachable modules.
Then, using data and our own expertise, we mapped skills against roles and levels and the modules against the skills and ta-da! Here is how to nail Excel for your role as envisioned by Filtered (presentation circa A.D. 2009):
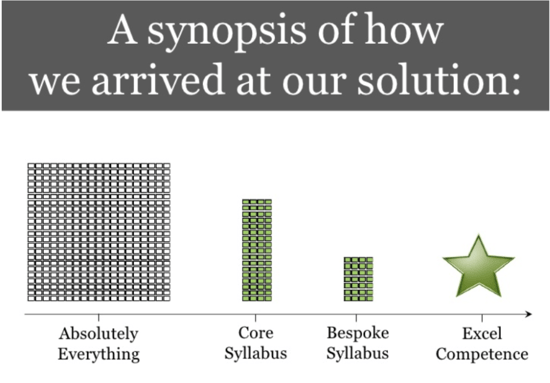
There was a lot more to it than that, of course, but here you have not only the prototype of all the adaptive corporate skill initiatives we see today but also the kernel of Content Intelligence.
The result is more efficient (saving about 35% of the user’s time) and effective (driving about 26% better knowledge transfer) upskilling.
But for input, you need to define your skills well and map them both to roles and content.
A lot of people liked our Excel course (1 million people bought it, in fact). So we doubled down: keeping our focus on adaptive learning, we extended the offering to the whole Microsoft suite and some common soft (or power) skills.
And it was now about much more than Excel. The core business relaunched in 2014 as Filtered.
And by 2017 we had a library of 30+ adaptive courses and a cool model for how skills, content can solve the 'productivity puzzle', anticipating in our very British way the mega-trend for upskilling that took hold of us all in the 2020s:
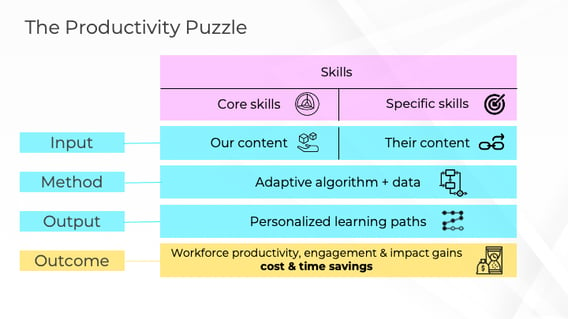
It was powered by a foundational framework of knowledge worker skills. In the process of developing this skill framework we learned a bunch of things:
… we found out how knowledge workers really spend their time (yes, 30 minutes of it is spent in spreadsheets, every day...)
….. we researched the cost of skill gaps at the level of the whole economy (it’s a lot)
…….. and we gazed at predictions for the future of skills from the World Economic Forum
This research into skills informed a lot of client work which saw us crunch a lot of data and develop a general method of prioritising skills that ultimately led to Filtered’s Skills Palette.
What was all that work intended to achieve?
Well, you see that ‘specific skills’ and ‘other content’ part of the diagram?

That red box, our clients told us, “we want that! Not just generic skills mapped to a generic skill framework. But our specific skills and our specific content! Why do we have to stick to your courses and content? Why can’t you map our own content to our own, nuanced, skills?”
We listened. But building an adaptive course for every combination of client skills and content felt impractical (although we note how some are gloriously succeeding at this task now). To solve any skill/content problem, the next phase involved something many readers will be familiar with: magpie, the world’s first learning recommendation engine.
Launched in 2017, magpie introduced a lot of things that have since become commonplace in the learning platforms: a skills-first view, a few onboarding questions to personalise your experience, curated content in personalised rows, a slick, mobile-first experience.
Netflix of Learning it wasn’t. But there’s no denying that the output looked not like a syllabus, but as a recommendation:
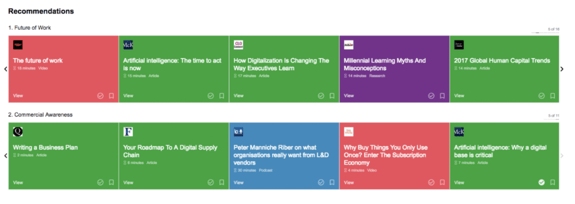
Underneath the hood magpie addressed the exact same challenge: syncing skills and content. In fact, it uses a knowledge graph to give every piece of content its own ‘skill signature’ so that the learning can be matched accurately to a learner profile.
Between magpie and Content Intelligence, the amount of content we had to deal with grew a lot.
The content that went into magpie was originally handpicked by the Filtered team. It was a list of literally 897 items, lovingly tagged by our own curation team, against our knowledge worker framework. Along the way, we developed and followed some important curation principles.
But soon clients started handing us whole libraries, their own content and big chunks of the web to tag against their skills and put into magpie.
So Content Intelligence evolved of necessity as we scaled up our tagging techniques, using increasingly sophisticated and scalable methods to tag our way through hundreds of thousands of resources.
Once tagged, the content could be curated.
Curation, the art of choosing (and framing) well, turned out to be a really important part of making a skills-based recommendation. Every instance of magpie (which became our smart LXP) was informed by our passion for curating the best content.
As we gained access to usage data from the product, we developed more ways of making sense of all of this learning content. For example, we learned that:
- High quality content had a head start in terms of user engagement. The lower the quality, the more precise the recommendation had to be to make it work. So quality was a key criterion for good curation in general.
- Content relevance could be measured and optimised by asking users to mark completed content as useful, not useful, or not relevant (the worst). And in turn, each piece of content bore a certain relevance and usefulness score specifically to certain skills...
- Format was important because different formats of learning fared better in different contexts (such as different times of day)
- Length, publisher, recency - all of these other fields were important filters too, depending on what you were learning or who you were choosing learning for.
We used these categories to provide really useful business intelligence on learning to our clients: we tried to help them understand which libraries were the most valuable, which skills they should focus on, and how both of these factors fed into a learning content strategy.
In other words, we had developed Content Intelligence.
Content Intelligence as it currently stands detaches itself from our own LXP. It recognises that the problem of syncing skills and content goes beyond any particular learning platform. Content Intelligence is adaptable to the nuanced skills of your organisation. Your skills, defined by you. Your content, built, bought or curated by you. Content Intelligence brings them together.
Every big organisation (and many small, forward-thinking ones) stands to benefit from Content Intelligence, whether they use Degreed, Cornerstone, Success Factors, our own LXP, or no such learning system at all.
If you understand how your content aligns with your in-focus skills you can:
- Save up to 30% of your licence fee costs for paid, third-party content (that’s £300k - £500k for big companies)
- Dramatically speed up the curation of learning pathways (think minutes instead of hours per pathway)
- And substantially improve the discoverability of content in your LXP (improving the # of relevant results from 1 in 10 to 9 in 10 for common but problematic LXP search terms).
These tangible, measurable and proven benefits are quite different to anything Filtered has achieved before. They represent a step-change in L&D practice overall. And the pursuit of these benefits is driving the emergence of Content Intelligence (CI) as a new category.
We’re telling the inside story to show how our fixation on skills and content is at the root of all we have done and all we do. Big concepts often begin in limited forms and, as history unfolds, reveal themselves fully (from Athenian democracy to the French revolution). Content Intelligence has emerged from a 13-year passion for and obsession with skills and content.