Once upon a time, there was a fairytale. It was such a special fairy tale. Only one copy was ever written out. It was the author’s single life work. Wonderfully written and beautifully illustrated, it would wring every human emotion from its reader, from joy to mirth to excitement to fear. It could teach and spark curiosity and magnify imaginations. But not a single person ever read it.
Here’s a way to think about the knowledge you can have about your learning content. There is you and your team. And there is your learning ecosystem. Both know certain things about the learning content you have.
You and your team will have a more generalised understanding, drawing on high-level, somewhat vague notions like reputation and quality, some other sources of data like usage and impact, sometimes there will be hard data, sometimes there will just be anecdotes. And occasionally there will be some fine detail (e.g. that TED talk about psychological safety by Amy Edmondson which the CEO and IT liked very much…). Of course, there are strict limits to what a person or even a large team of people can carry around in their heads.
Your learning ecosystem has knowledge of a different kind. It comes in the form of data and metadata. At its best, metadata is complete, inconsistent, up-to-date and fit for your organisation’s various purposes. Unfortunately, metadata checks all these boxes.
So there are limitations to both kinds of knowledge about learning content. If we view human knowledge as primary and the ecosystem’s knowledge as secondary, we can construct a 2x2 matrix (which, for me, makes this even possible, cognitively) which suggests some particular actions to take which might strengthen your learning content strategy as well as how you think about it:
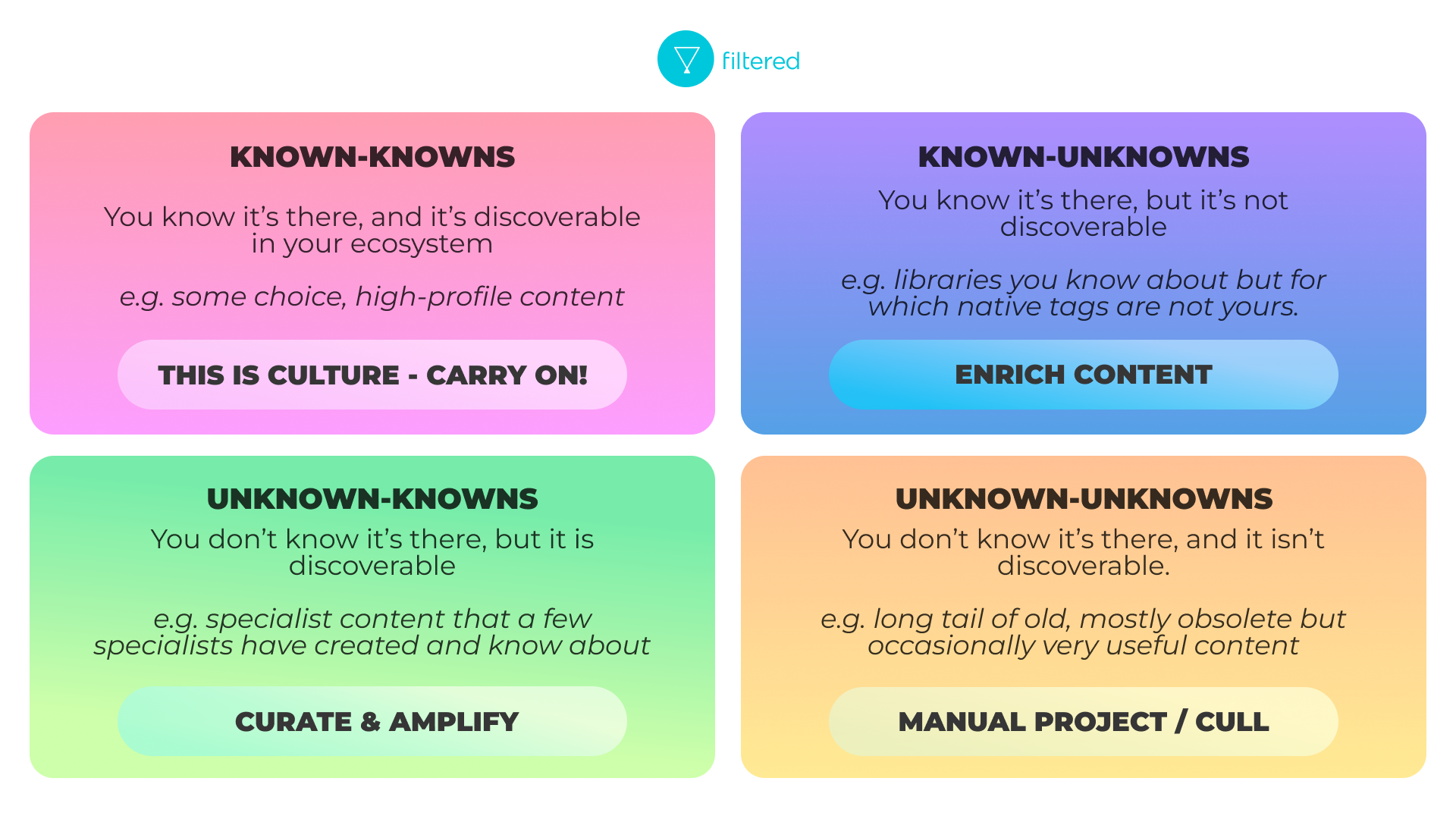
Each quadrant is interesting.
Known-knowns
Every organisation should have a small number (could literally be one; some companies issue a carefully-chosen book to all new joiners - see thought experiment described here) of assets that are known by everyone that aligns to the culture and industry of the organisation. These are not compulsory in the way that most mandated content is, but they are so embedded that it would be a highly rebellious and misguided employee that avoided it.
This kind of special content can precipitate lovely, enriching water-cooler moments. If you don’t have this - and most organisations don’t - think about establishing it.
Known unknowns
You know you’ve got plenty of content on, say, sustainability in your sector (the vendor promised you as much and you saw it) but it’s not tagged well or with the search terms your people actually use, so they don’t find it. Make it discoverable by finding a way to tag it appropriately and in such a way that people will find it.
The Filtered team can help, formally or informally.
Unknown-knowns
You don’t know about it but it’s well-tagged and discoverable. Maybe there’s a library that has a bunch of scientific content which your people need and this is a surprise to you. Or there’s a folder of data analytics material drawing on sample data from your company which you didn’t know about.
If this is well-tagged already, you in L&D can seek it out and promote it through pathways, playlists, plans and campaigns.
In our experience, such content usually needs a little algorithmic magic dust before it will be ready for wider circulation. But when it’s ready this is wonderful - you can drop these treats in the paths of your people, step back and wait for the praise and gratitude.
Building pathways at scale is also something the Filtered team can help with, formally or informally.
Unknown-unknowns
(Also known as learning gunk.)
Every company has huge amounts of this. This is almost always internal, proprietary, self-built content. It tends to be incorrectly or inconsistently tagged, or not tagged at all. That would be fine if none of it were useful - you could just archive it all. But it’s often the most relevant, impactful material in your organisation’s possession. Filtered's algorithms can salvage some of this at speed if there are even a few words in the metadata.
For the rest, you’ll need to make a call to cull or instigate some manual work to bring this back to life. With almost all the clients we’ve worked with on this, we’ve separated these items out and dealt with them in a Phase Two.
You will probably notice, that there’s far more content, by volume, in the last three sections. The first section is important in it is too.
It’s worth doing a mental pirouette with this. Rather than thinking of your job as helping learners find learning, think of it as helping the learning to find its learner, the fairytale to find its reader…so they may live and learn happily ever after.
Do you have content that needs enriching, amplifying or culling? Our team can help, with a 30-minute Content Clinic.