THE FILTERED EVIDENCE LIBRARY
🔎 This page provides evidence for our key product claims. It's designed to be used as an off-the-shelf resource for business cases to introduce Filtered to your organisation. If you would like more tailored support with evidence, we're happy to help with that too. We will add to this evidence library as we go.
Contents
Time saved through algorithmic tagging
Ease of producing and sharing playlists
Why build playlists or pathways?
Algorithmic tagging precision
💡 We have demonstrated that algorithmic tagging produces results as pure and precise as skilled human curators.
'Precision' is one standard measure of the quality of tagging. It represents how 'pure' tagged output is - what proportion of algorithmically tagged assets are tagged correctly.
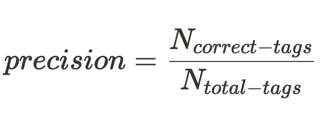
(For comparison, another metric, 'recall', the flip-side of tagging quality - how good an algorithm is at finding needles in haystacks. It's the proportion of assets that are relevant to a skill in the whole asset database that are found by the algorithm.)
To measure precision we need a gold standard for tagging - we need to know when the tag the algorithm has applied is right. We use skilled human curators with expertise in the skill area to define this standard.
So when we talk about precision, we mean the proportion of the time a skilled curator agrees with the algorithmic decisions.
We measure precision all the time to ensure quality in our CI products in real-world conditions. For example with a global pharmaceutical we conducted a controlled experiment using their skills taxonomy and real-world assets from their LMS, resulting in an overall precision of 83%.
How good is 83% though? Again, we use human experts as our standard. When we measure the precision of one expert's tagging against another, we achieve results in the range 60-80%, depending on the skill. So here algorithmic tagging is at least as precise as human expert tagging.
This report provides more detail on these findings.
Time saved through algorithmic tagging
💡 For a library of 30,000 learning assets, and a framework of 40 skills, algorithmic tagging saves time equivalent to half a year's work for a skilled human curator.
Algorithmic tagging is almost instant once tagging models have been configured, whereas human curation is of course time consuming.
The time taken for a human curator to tag an asset increases with the size of the skills framework; it's harder to decide accurately which of 50 skills applies to an asset than which of ten.
We measured (in a two week sprint where we needed assets well tagged to a variety of skills frameworks) the time it takes skilled human curators to tag content well, and used the results to build this calculator.
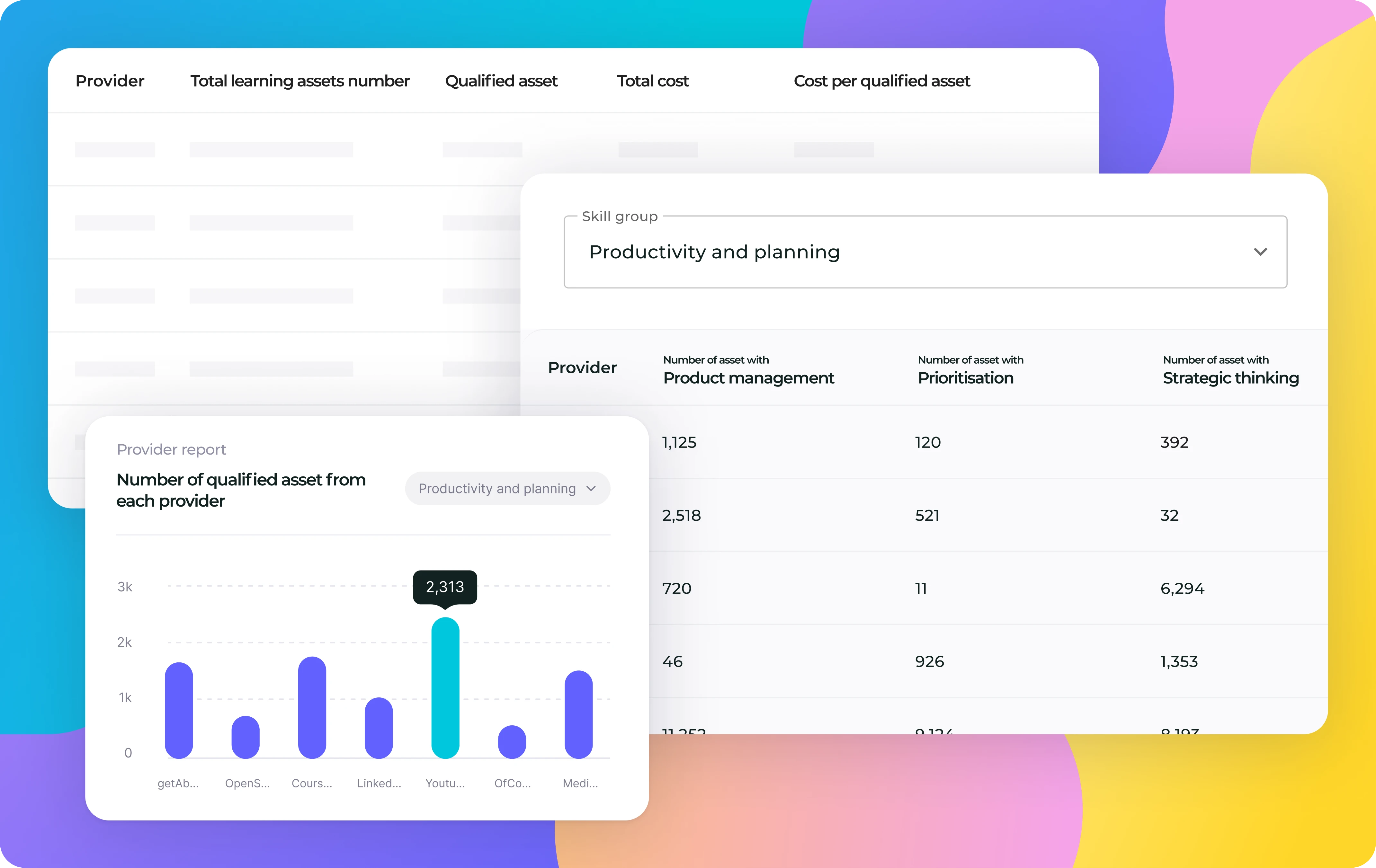
 Example output from time-saved model
Example output from time-saved model
The model goes on to calculate a cost saving equivalent to the time saved, based on a salary assumption.
For both human and algorithmic tagging, QA is needed (depending on the use case which affects the consistency required). The time required here is the same so doesn't feature in this time-saving calculation.
Impact of CI on LxP discovery
💡 The ROI of LxP and content spend can be hobbled by poor discovery within LxP - irrelevant search returns, poorly personalised recommendations and valuable content left buried beneath dross. In a carefully controlled study with a global bank, we demonstrated that CI algorithmic enhancement of metadata within Degreed reduces irrelevant search results on the first page from up to 90% to 10% for all search terms.
Search results can be poor within LxP because of a collision between scrappy metadata (titles, descriptions, skills tags, language labels etc.) and simple search algorithms. We quantified the effect CI has in an experiment with our partner, a global bank.
Based on recorded searches in Degreed in the previous 3 months, we selected sample search terms representative of different categories of skill or topic: broad & narrow skills, soft and hard, common and niche etc. Ranging from growth mindset to sustainability to data analytics to Kubernetes.
We recorded the search results for the sample terms, then enhanced the metadata within Degreed using CI, and repeated the searches. We combined, randomised and blinded the search results to remove the possibility of bias, and asked subject matter experts within the bank to assess the search results for relevance.
Between 70-90% of searchers do not look further than the first page of search results in Google, and this reliance on the top of the prioritisation seems to be even more pronounced in LxP. We therefore selected a metric of % relevance of the first page (top 20) results to compare the quality of the search pre- and post- CI enhancement. Subject matter experts rated search results as relevant (2 points), somewhat relevant (1 point) or not relevant (0 points).
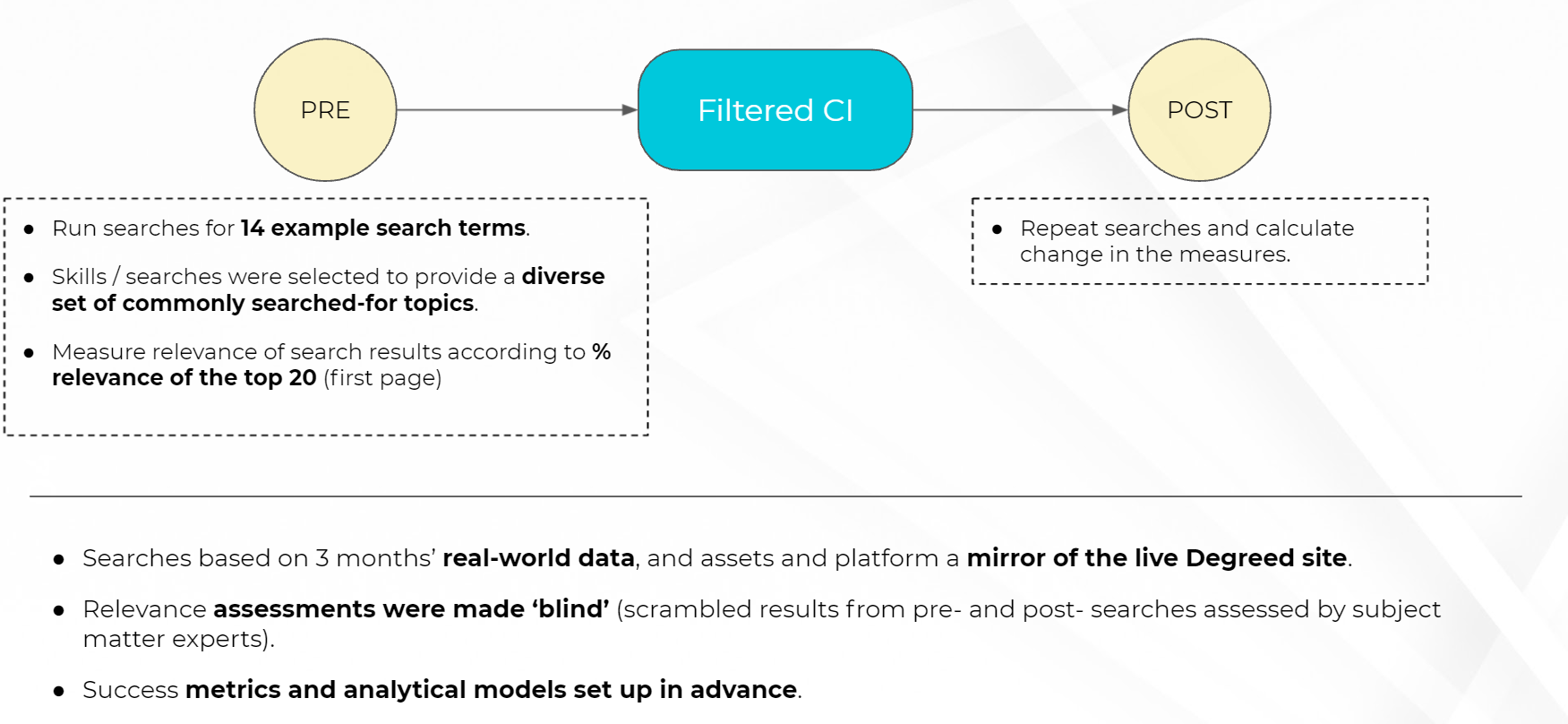
We found that relevance before the application of Filtered CI was very variable, ranging from 8% to 100% on the first page. Application of CI to skills tags brought the relevance above 50% for every search term; tagging appropriately to asset language raises the relevance figure to 90% or higher for all terms.
Ease of producing and sharing playlists
💡 Content intelligence makes it extremely quick and straightforward to produce and share playlists from diverse content libraries. Because content is prioritised for the curator according to its predicted relevance, curation decisions can focus on which of several great assets fit the context best, rather than searching for needles across haystacks.
Why build playlists or pathways?
💡 Learners value recommendations in the form of structured playlists more highly than simply relevant assets, such as you would see at the top of a successful search. In a controlled study, 92% of reviewers preferred structured playlists over simply-relevant content.
Creating playlists takes time*, and relevant content can often be found through search or algorithmic feeds - so why invest in building them?
In a controlled experiment, we tested subject matter experts’ opinion of playlists of five assets that were chosen to be coherent, ordered and diverse, compared with identically-presented sets of simply the five assets most relevant to the skill or topic.

We were careful with the design of the experiment:
- Playlists were reviewed blind (reviewers didn’t know which variant was which, or how the variants were constructed, and they were presented in a randomised order).
- Two variants were produced for each of six diverse playlist topics, including ‘Authentic leadership for first time managers’, ‘Agile mindset’, ‘Sales execution’ and ‘Machine learning using Python’.
- Reviewers were chosen so the playlists were relevant to their role: for example, sales professionals reviewed the ‘Sales execution’ playlists.
The results were unequivocal - in 92% of cases reviewers preferred the structured playlists over the simply-relevant content.
This strong preference is borne out in engagement stats. In most platforms, curated content dominates opens and completions, with most learners reaching content via built plans and playlists rather than search or algorithmic feeds.
* Although much less time with CI - see: Ease of producing and sharing playlists
